Table of Contents
- Penjelasan Tentang Random Forest
- Langkah-Langkah Random Forest
- Contoh Dataset Random Forest
- Spesifikasi Aplikasi
- Halaman Login
- Halaman Dashboard
- Halaman Dataset
- Halaman Data Mining Random Forest
- Halaman Inisial Proses
- Halaman Prediksi
- Tree Hasil Prediksi
- Halaman Performance Data Mining Random Forest
- Hasil Performance
- Bagaimana Untuk Mendapat Aplikasinya ??
- Tonton Video Aplikasi Ini & Review Orang-orang terkait Aplikasi Ini
Penjelasan Tentang Random Forest
Data mining random forest adalah algoritma machine learning yang digunakan untuk tugas-tugas klasifikasi dan regresi.
Algoritma ini berdasarkan konsep ensemble learning, yang menggabungkan prediksi dari beberapa model pembelajaran mesin untuk meningkatkan kinerja dan ketahanan terhadap overfitting.
Seperti sebuah hutan yang terdiri dari banyak pohon. Setiap pohon itu adalah model yang dapat memprediksi sesuatu, seperti kategori atau angka
Langkah-Langkah Random Forest
Berikut adalah langkah-langkah untuk membangun model Random Forest:
- Ambil sampel acak dengan penggantian (bootstrapping) dari kumpulan data pelatihan. Ini berarti beberapa data dapat muncul lebih dari sekali, sementara beberapa data mungkin tidak muncul sama sekali dalam setiap sampel.
- Bangun pohon keputusan menggunakan sampel data tersebut. Pada setiap simpul dalam pohon, algoritma memilih fitur acak dari subset fitur yang tersedia dan membagi data berdasarkan aturan pemisahan (seperti indeks Gini atau entropi).
- Ulangi langkah 1 dan 2 untuk membangun sejumlah pohon keputusan. Jumlah pohon ini ditentukan sebelumnya oleh pengguna sebagai parameter algoritma.
- Ketika melakukan prediksi, setiap pohon dalam hutan memberikan prediksi sendiri. Untuk tugas klasifikasi, hasil akhirnya dapat ditentukan berdasarkan mayoritas suara dari semua pohon dalam hutan. Dalam regresi, rata-rata hasil prediksi dari semua pohon dapat digunakan.
Makin pusing ?? hehe.. gak usah fokus-fokus banget sama teorinya diatas, cukup fokus sama aplikasi yang akan saya jelaskan dibawah ini, oke ??
Contoh Dataset Random Forest
| sepal_length | sepal_width | petal_length | petal_width | species |
|---|---|---|---|---|
| 5.1 | 3.3 | 1.7 | 0.5 | setosa |
| 5.2 | 3.5 | 1.5 | 0.2 | setosa |
| 5.7 | 4.4 | 1.5 | 0.4 | setosa |
| 5.4 | 3.9 | 1.3 | 0.4 | setosa |
| 5.5 | 3.5 | 1.3 | 0.2 | setosa |
| 4.6 | 3.2 | 1.4 | 0.2 | setosa |
| 4.4 | 3.2 | 1.3 | 0.2 | setosa |
| 4.7 | 3.2 | 1.6 | 0.2 | setosa |
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.6 | 3.4 | 1.4 | 0.3 | setosa |
| 5.2 | 3.4 | 1.4 | 0.2 | setosa |
| 5.2 | 4.1 | 1.5 | 0.1 | setosa |
| 4.3 | 3 | 1.1 | 0.1 | setosa |
| 5 | 3.4 | 1.6 | 0.4 | setosa |
| 4.8 | 3.4 | 1.9 | 0.2 | setosa |
| 4.4 | 2.9 | 1.4 | 0.2 | setosa |
| 4.8 | 3 | 1.4 | 0.1 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
| 4.8 | 3 | 1.4 | 0.3 | setosa |
Data yang digunakan adalah data dengan atribute numerik dan label alphanumerik, seperti contoh diatas ini, Yap betul, data mining random forest memang jenis algoritma supervised karena membutuhkan label, berbeda seperti algoritma-algoritma unsupervised lain seperti Kmeans
Spesifikasi Aplikasi
- PHP Versi 7.4 / 8.0 (Apache)
- MySQL
- Codeigniter 4
- Bootstrap 5
- HTML, CSS, JS
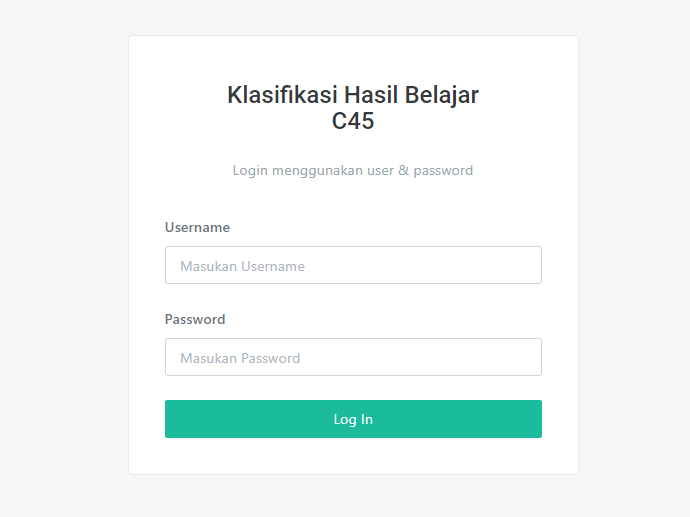
Halaman Login
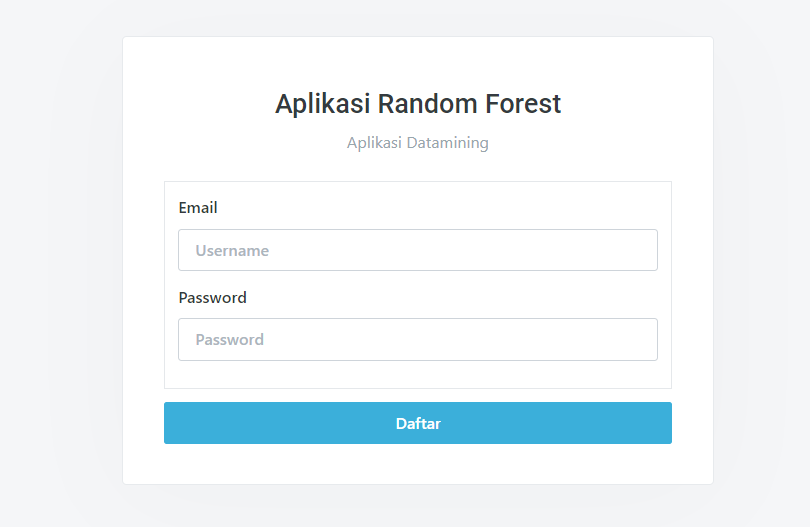
Sebelum masuk kedalam aplikasi user wajib untuk login dengan memasukan email & password kedalam form login ini, email&password tadi akan di validasi oleh sistem apakah sama dengan yang ada pada tabel users di database
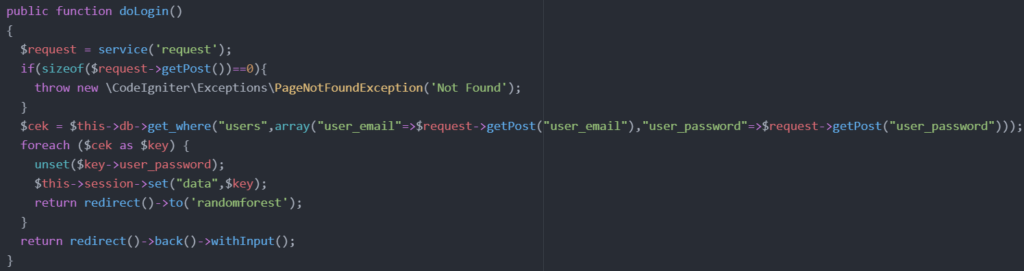

Ketika hasil benar, maka sistem akan mengaktifkan session nya dan mengarahkan (redirect) ke halaman randomforest
Halaman Dashboard
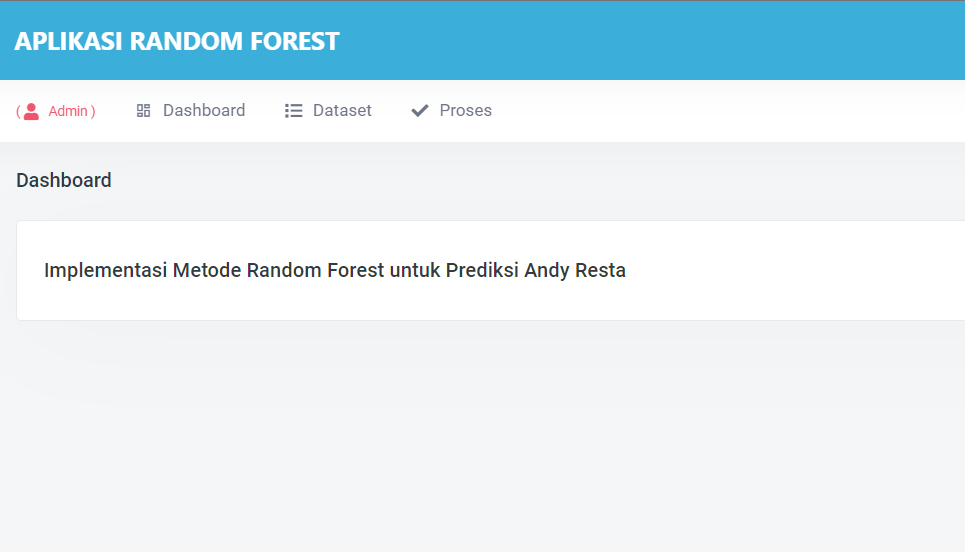
Halaman dashboard ini masih sangat sederhana sekali, jika kalian sudah mendapat source code nya kalian bisa memodifikasi sesuai dengan imajinasi kalian, halaman ini letaknya ada pada pada file App/Views/module/dashboard.php
Berikut isi dari source code halaman dashboard,
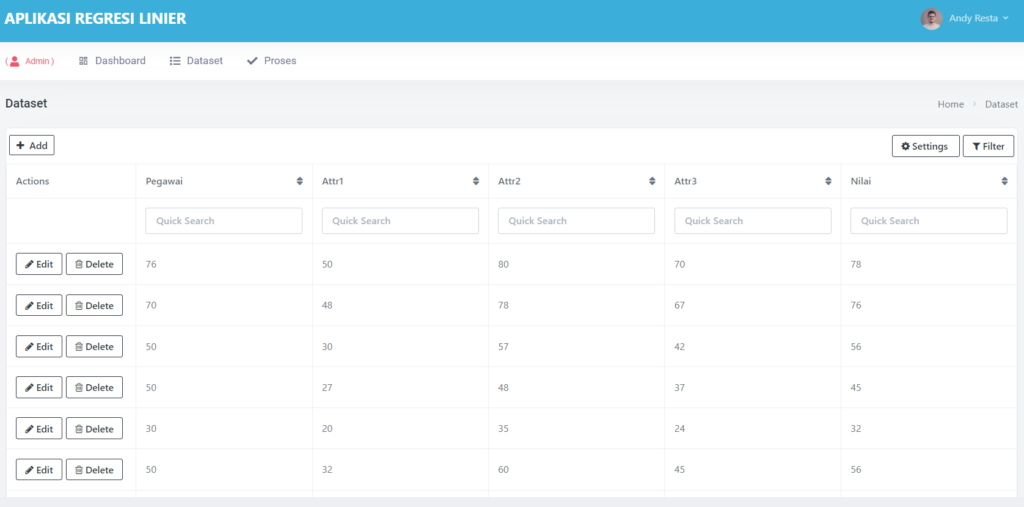
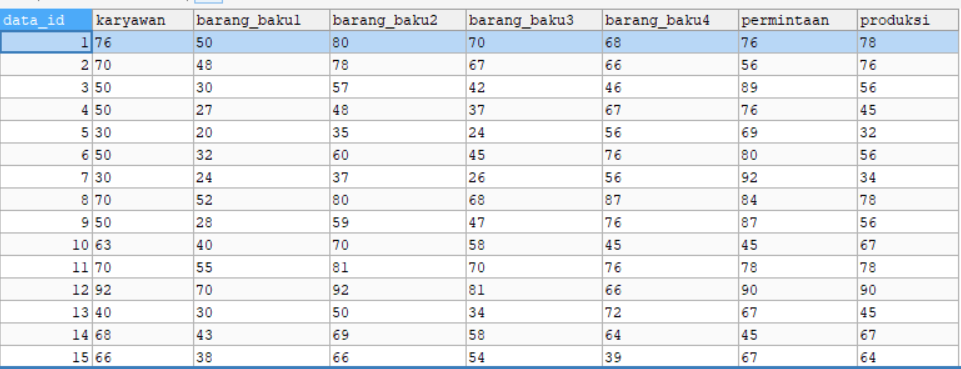
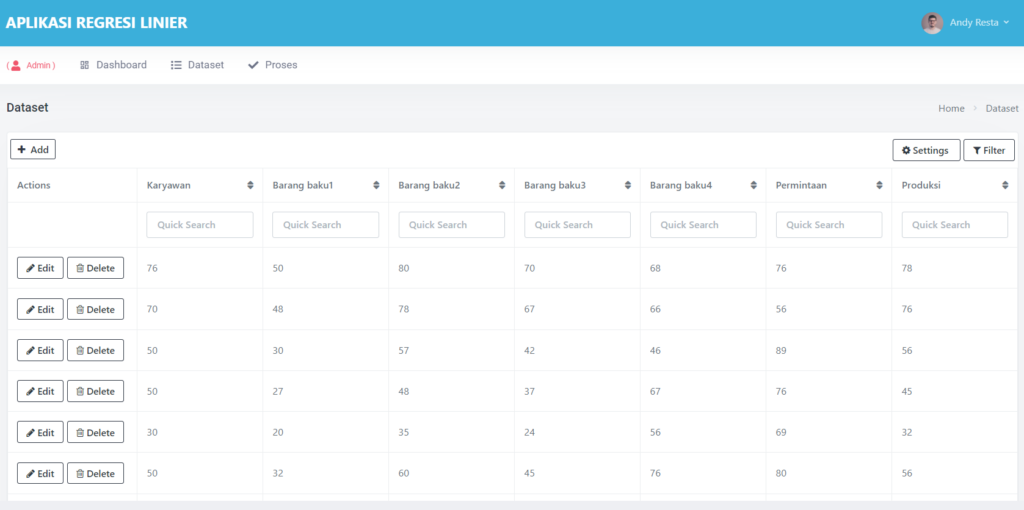
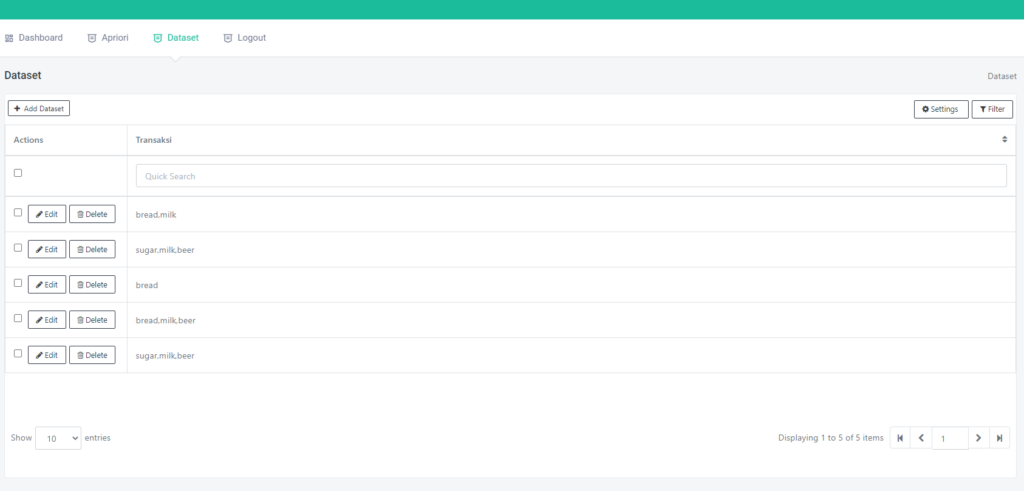
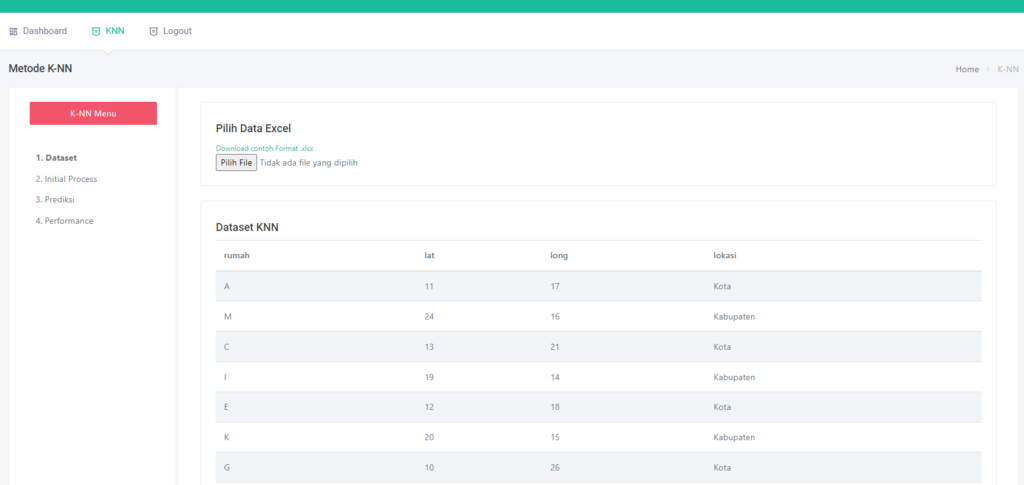
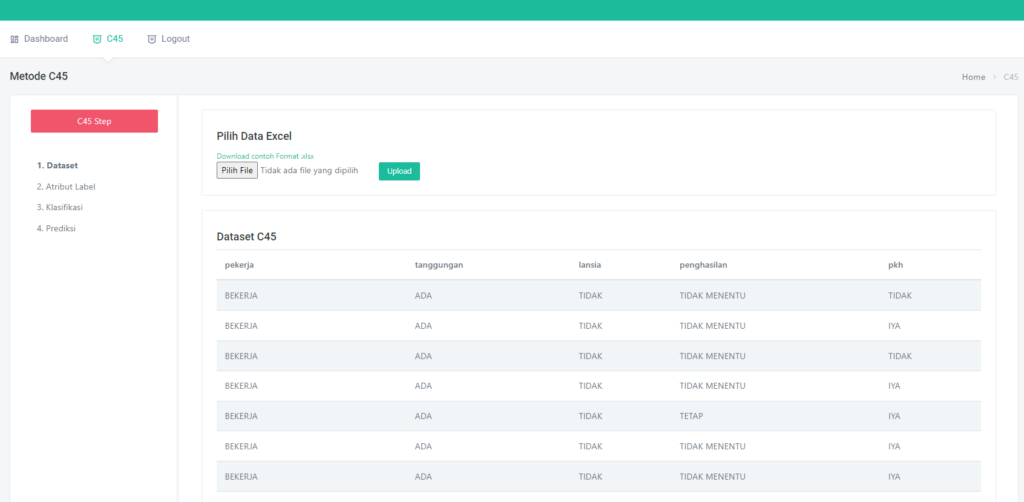
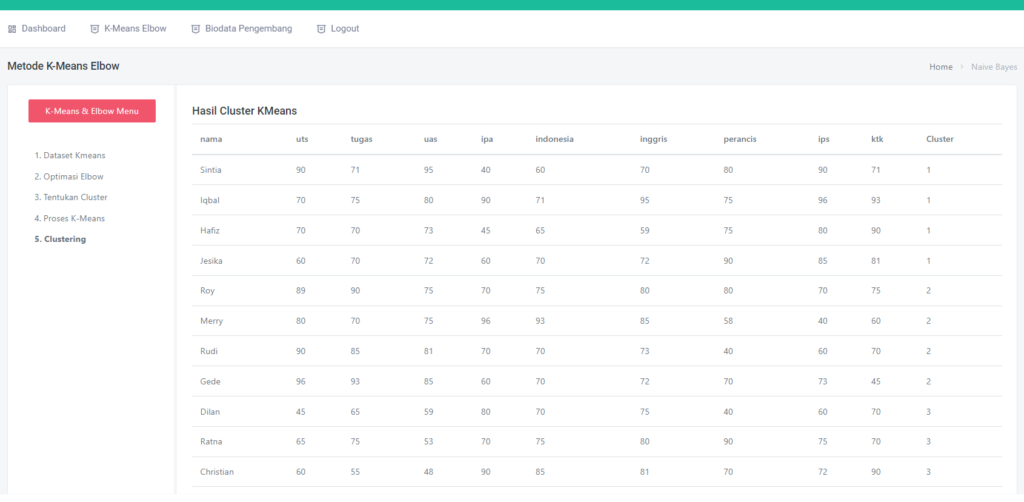
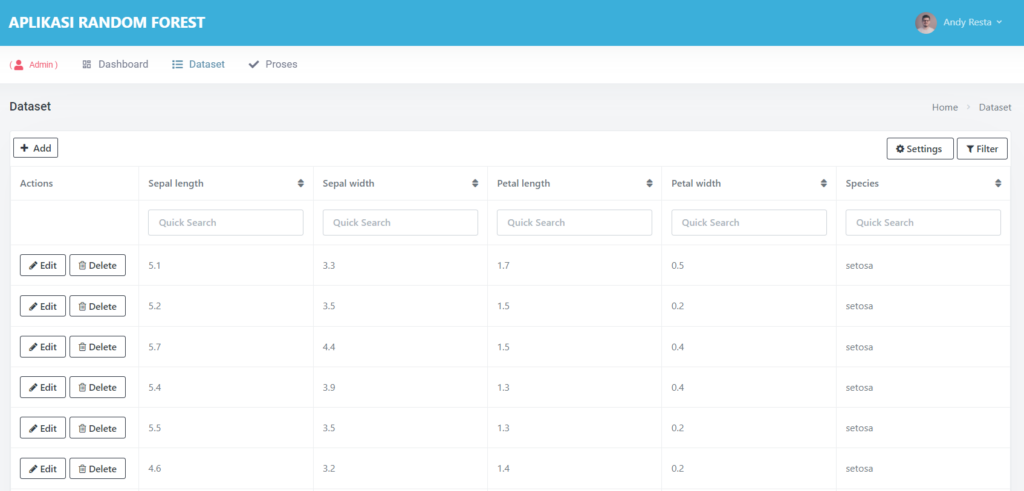
Halaman Dataset
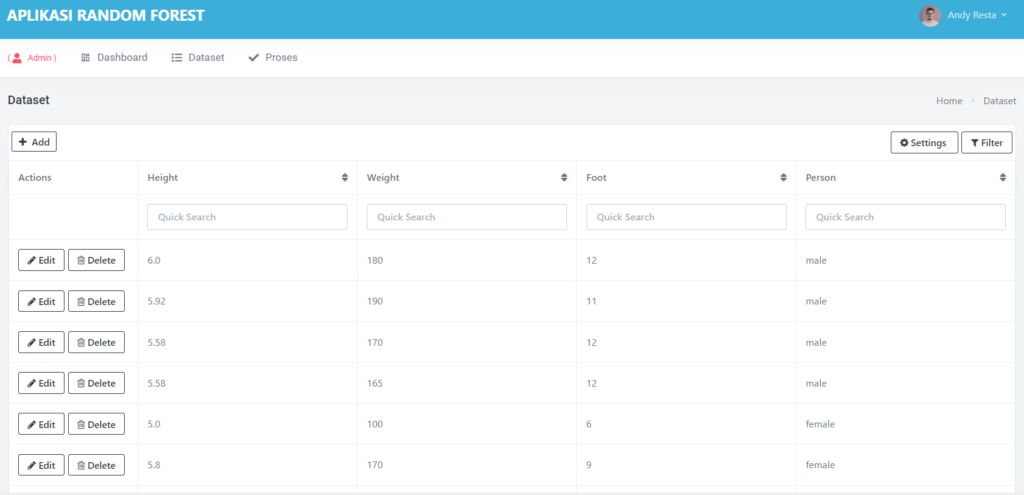
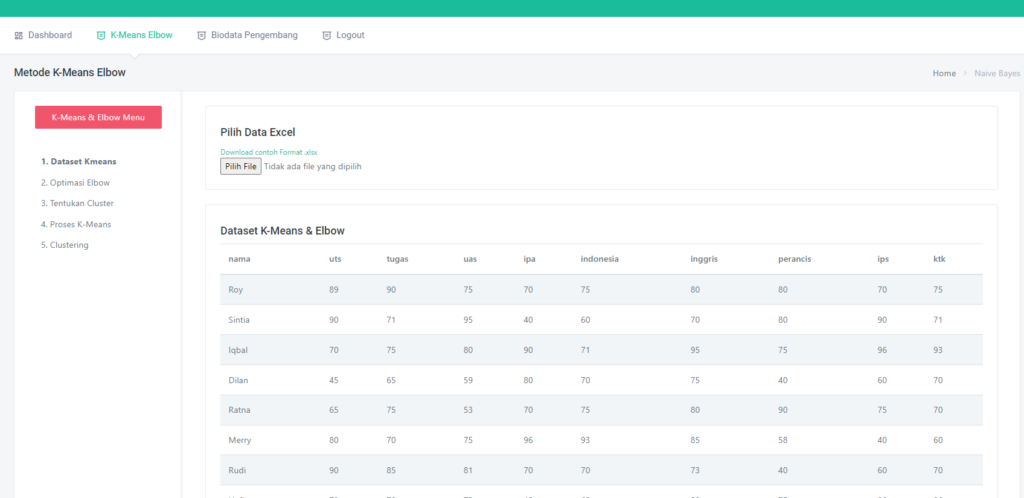
Pada dataset ini sudah dilengkapi dengan CRUD, jadi kalian bisa menambah, edit, hapus dataset sesuka hati, Tidak hanya itu, dataset ini juga sudah tersedia fitur searching by kolom
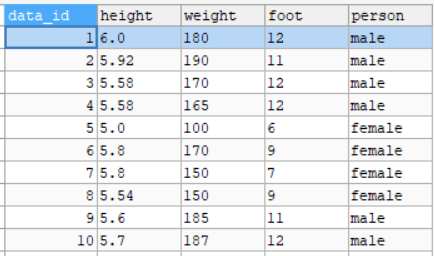
Diatas ini adalah tabel dataset, dengan atribute sepal_length, sepal_width, petal_length, petal_width dan label species
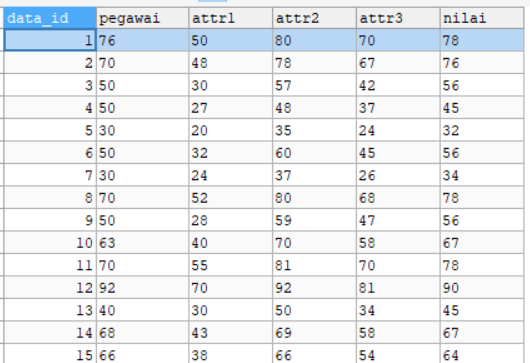
Bagaimana Jika Saya Punya Dataset yang Beda ??
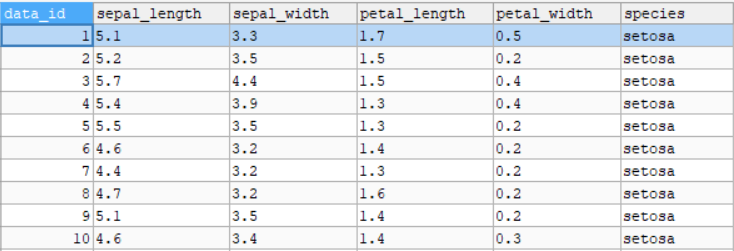
Sebenarnya kalian tinggal buat tabel baru lagi dengan nama dataset, dan kolom-kolom nya disesuaikan saja dengan dataset punya kalian, saya kasih contoh dibawah ini,
Lalu bagaimana dengan fitur menu dataset di aplikasi ??
Secara otomatis fitur dalam aplikasi akan menyesuaikan dengan tabel dataset yang kalian buat, pada algoritma data mining random forest juga secara otomatis menyesuaikan dengan apa yang ada pada fitur dataset ini
Menarik bukan ??
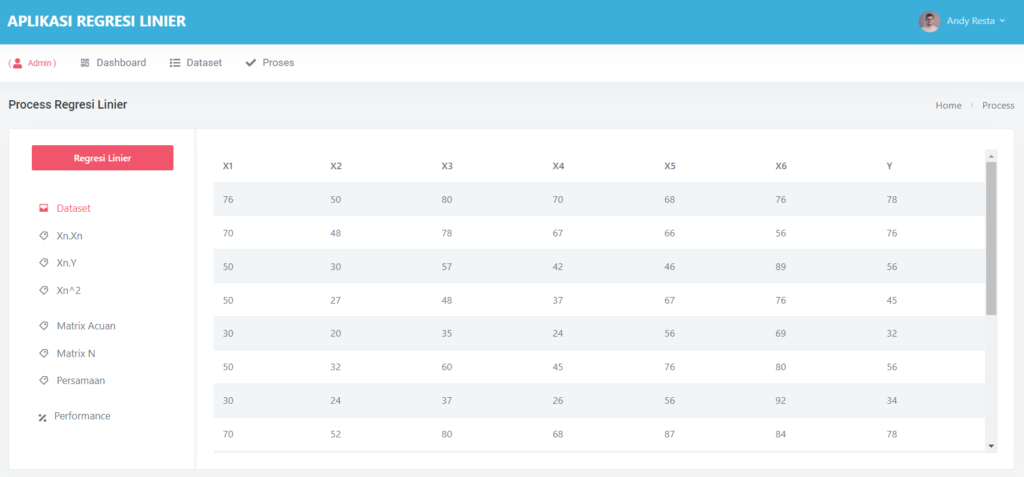
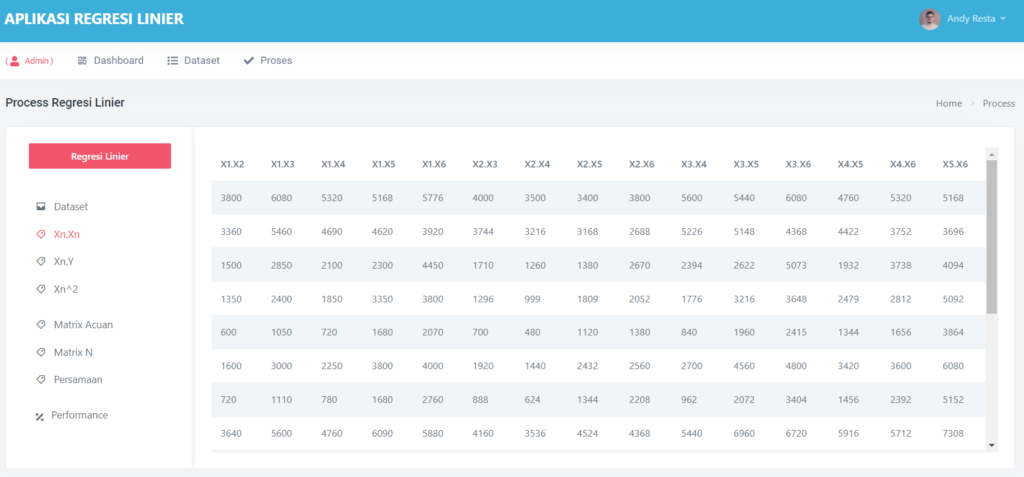
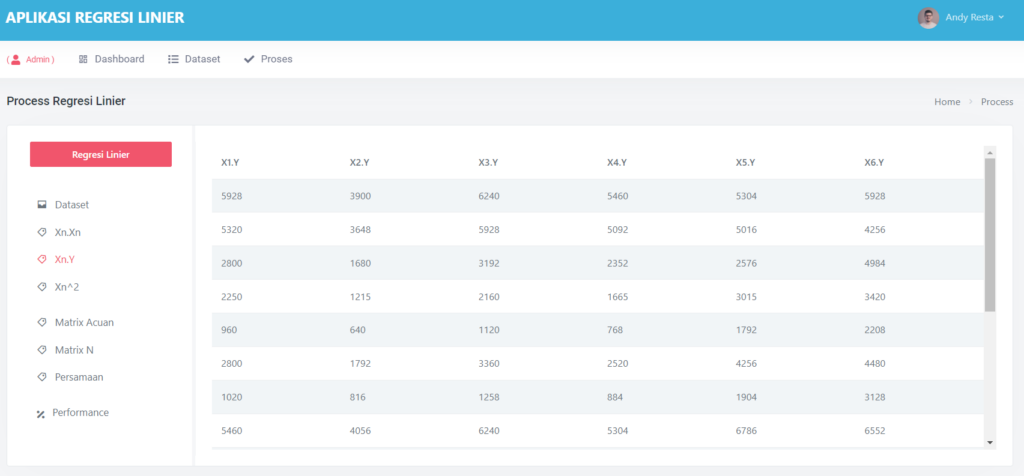
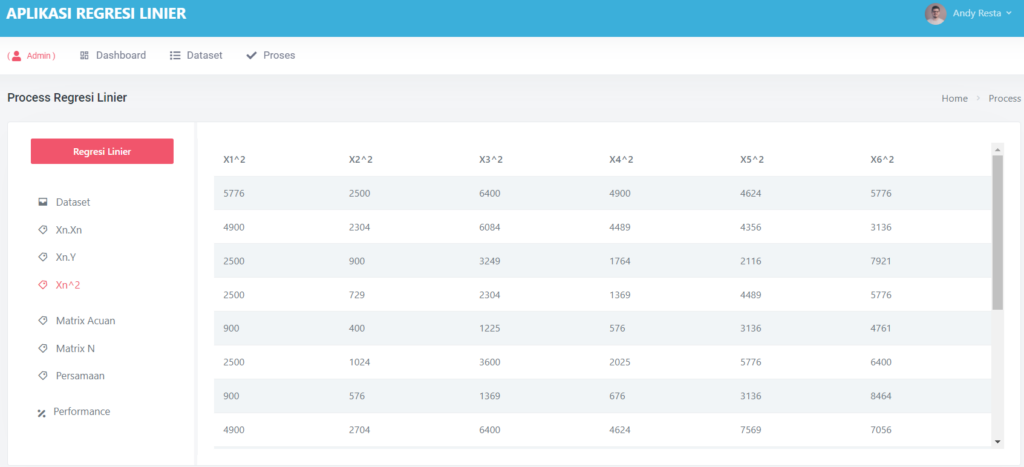
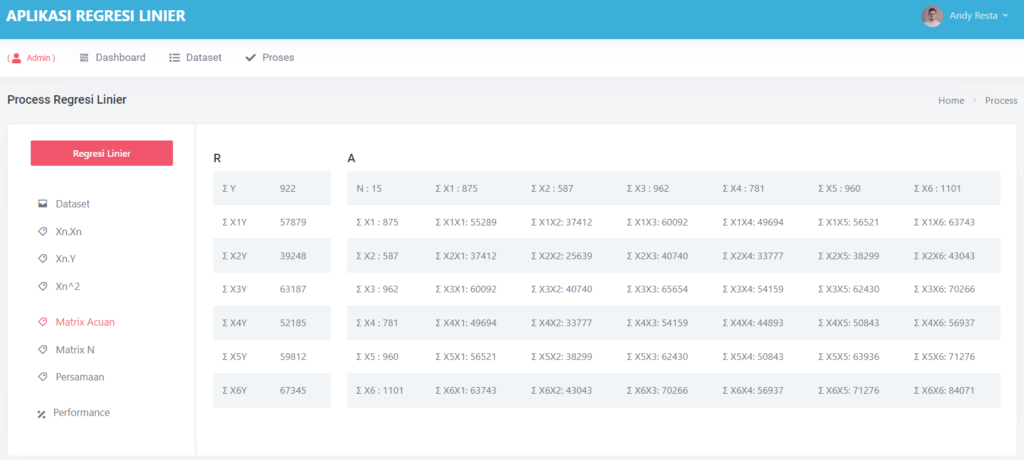
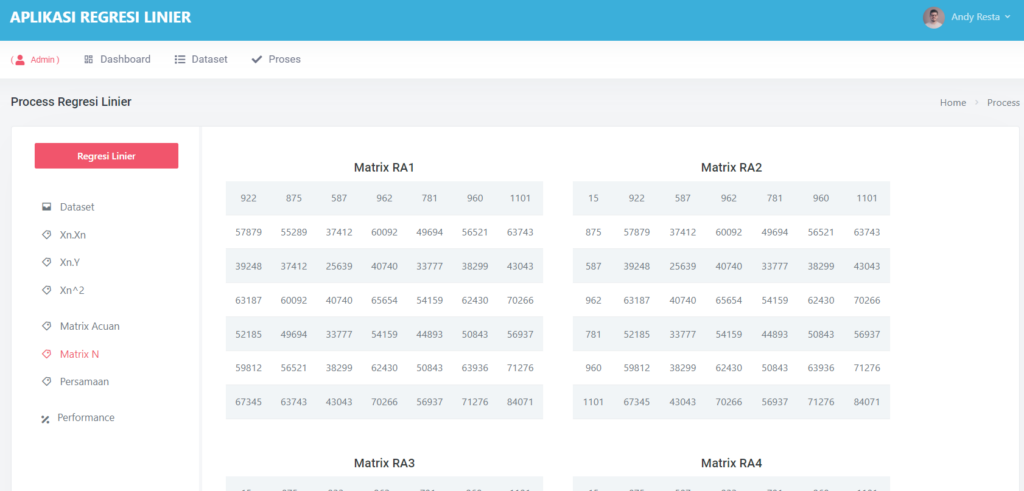
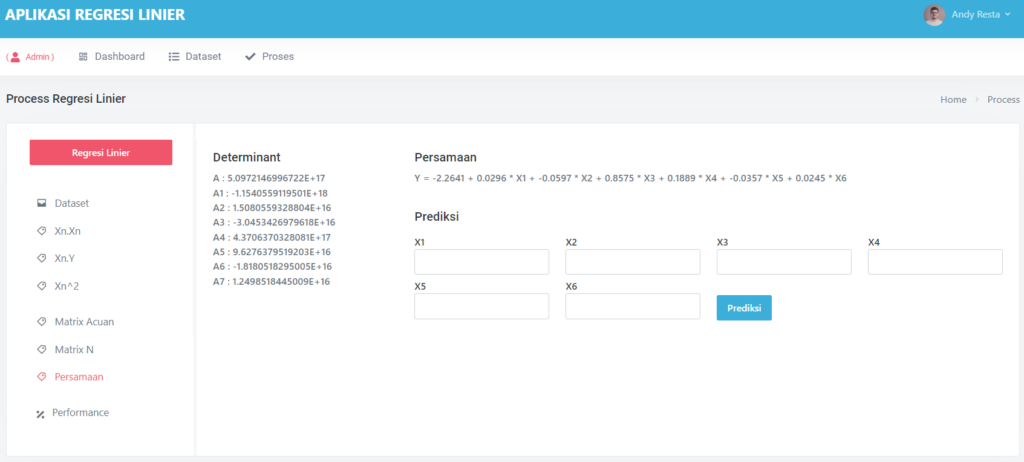
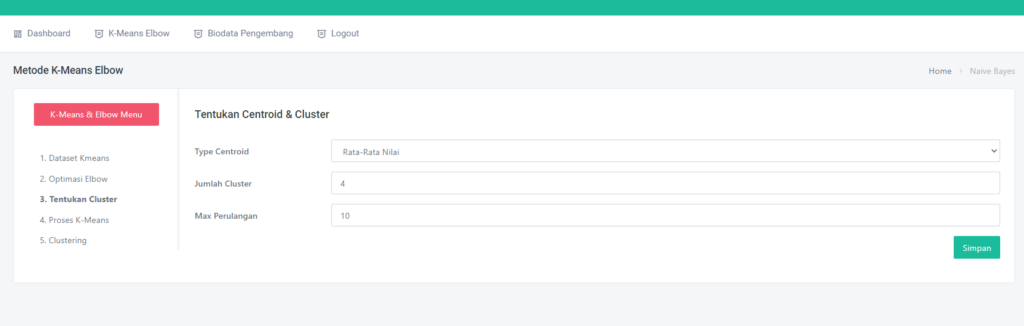
Halaman Data Mining Random Forest
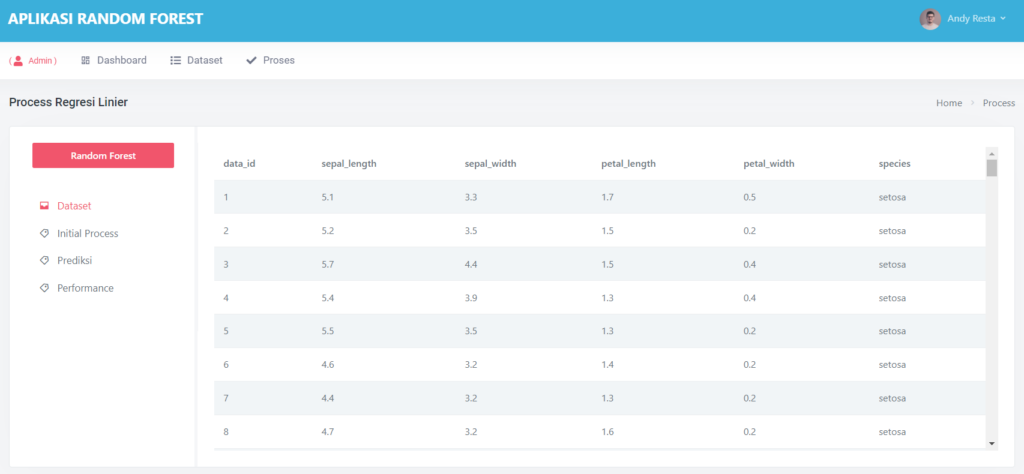
Pada halaman proses, terdapat sub menu dataset, ini akan menampilkan semua dataset yang akan di proses,
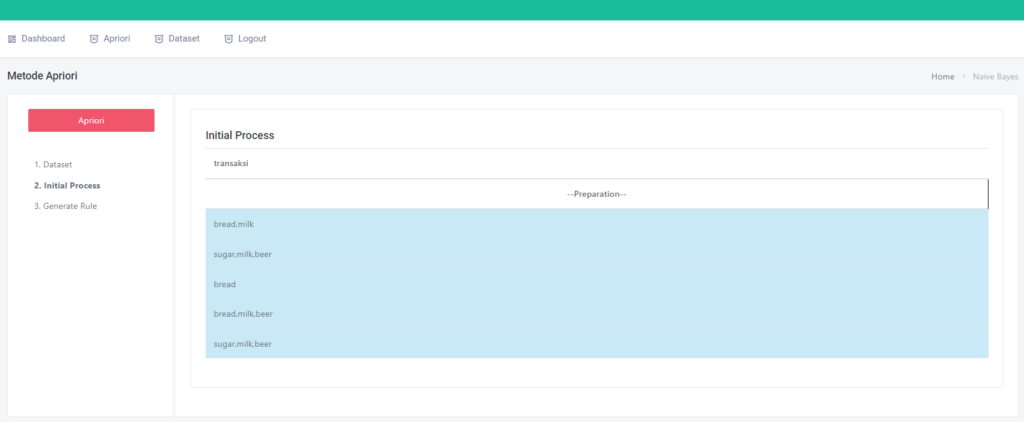
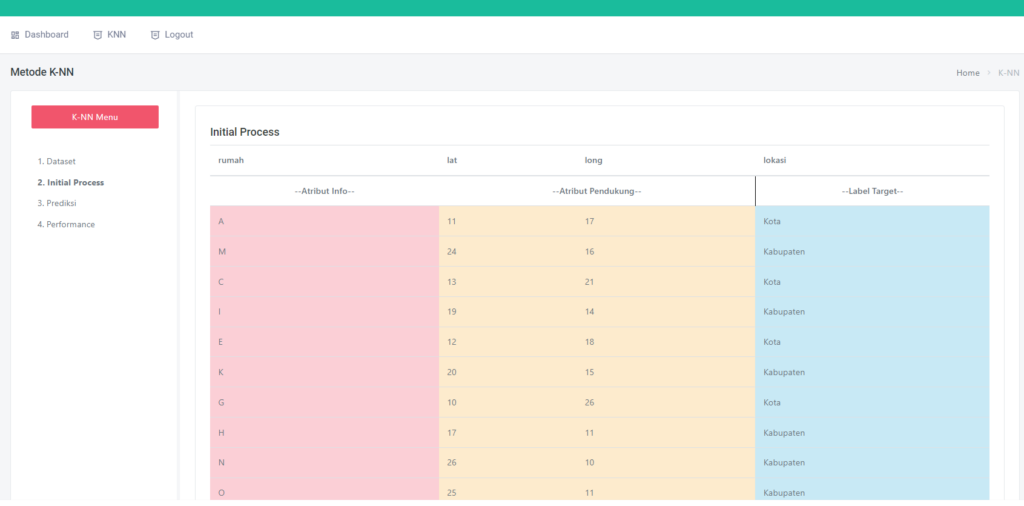
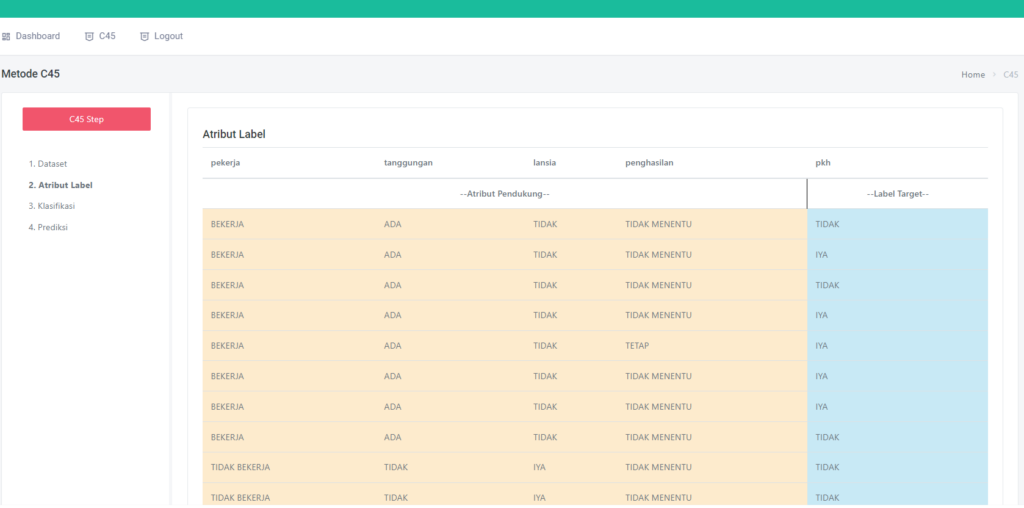
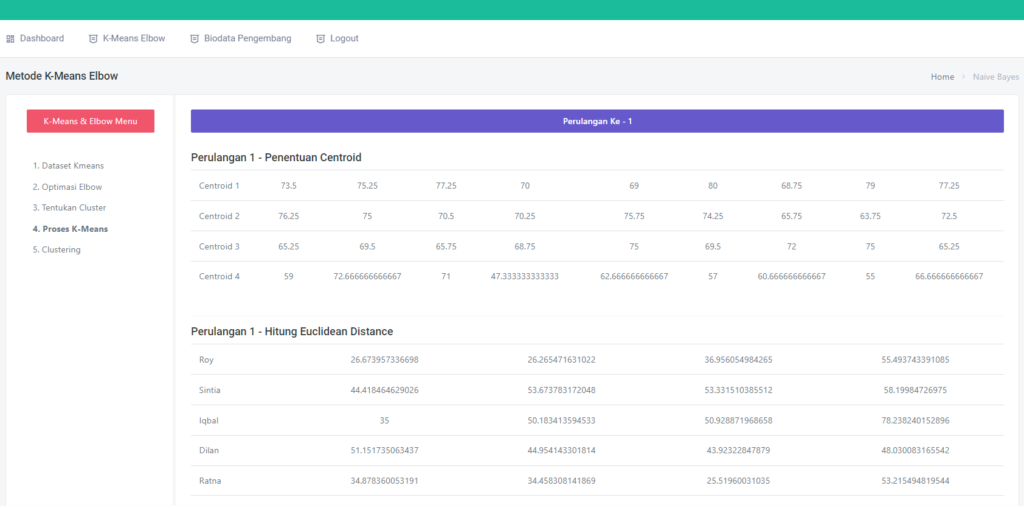
Halaman Inisial Proses
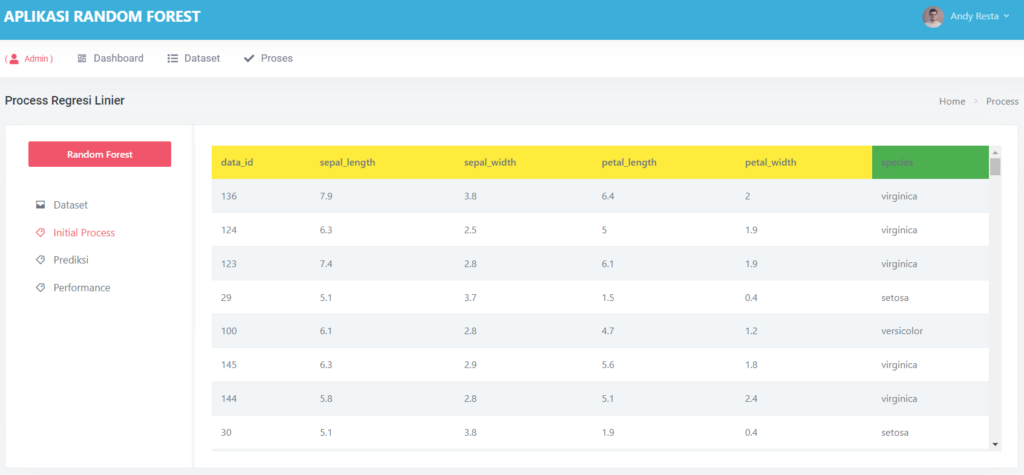
Pada halaman ini dataset yang sudah ada di pisahkan kedalam 2 bagian, yaitu atribute dan label, terlihat pada kolom berwarna kuning merupakan atribute dan kolom yang berwarna hijau adalah label (label selalu di sebelah ujung kanan)
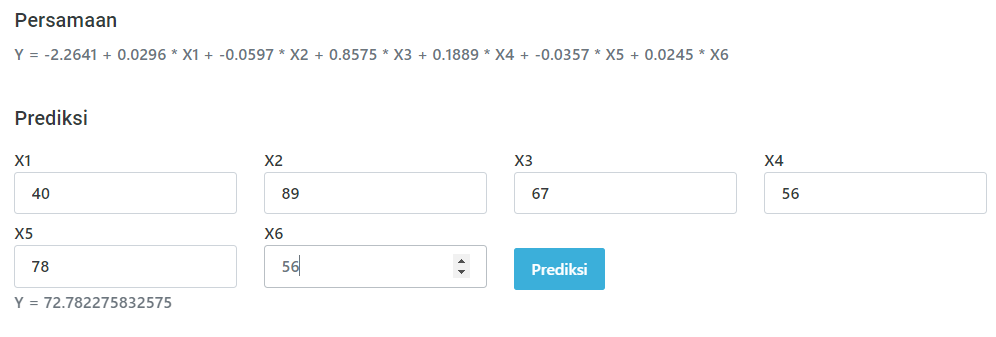
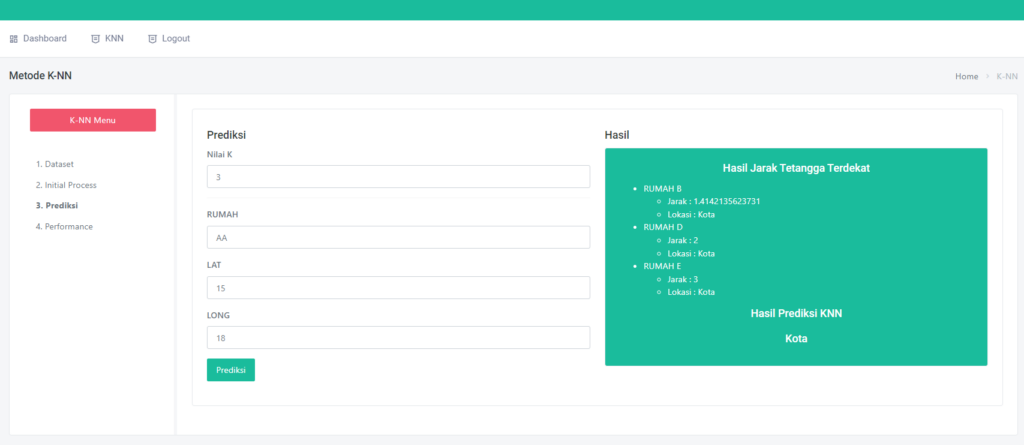
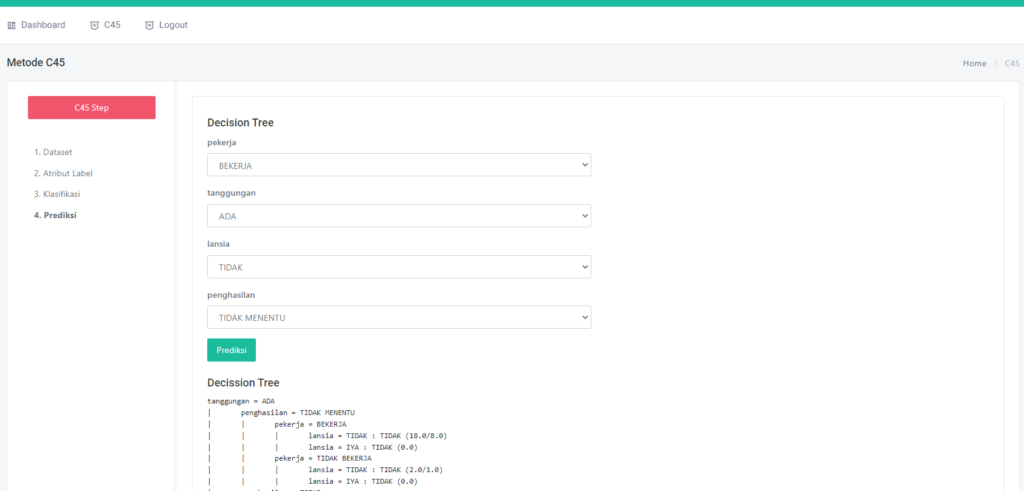
Halaman Prediksi
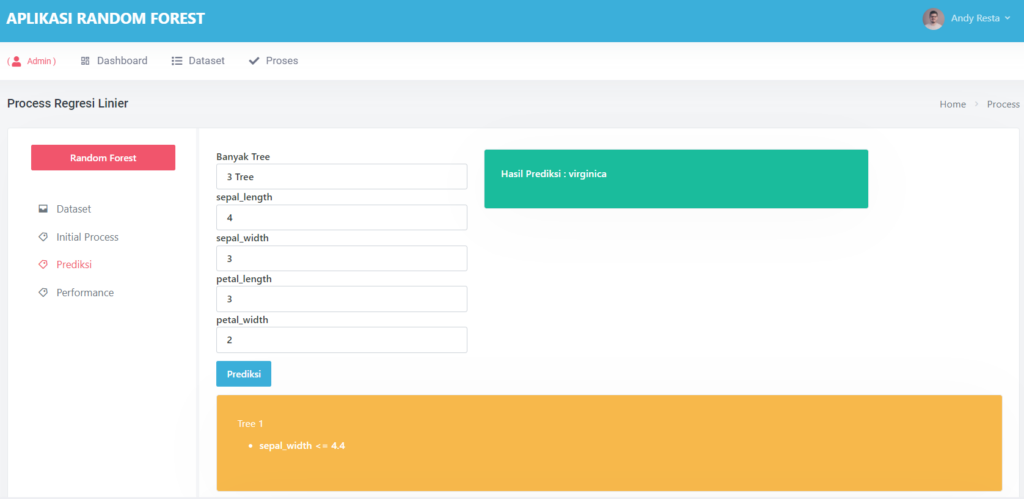
Pada halaman prediksi akan menampilkan form inputan sesuai dengan kolom atribute dataset, dengan ada tambahan field Banyak Tree, banyak tree ini bebas kalian akan memilih berapa tree yang akan di generate,
Ketika kalian sudah mengisikan dan klik tombol “prediksi” maka secara otomatis hasilnya akan terlihat di sebelah kanan yang berwarna hijau, sedangkan Hasil tree nya akan tampil di bawahnya
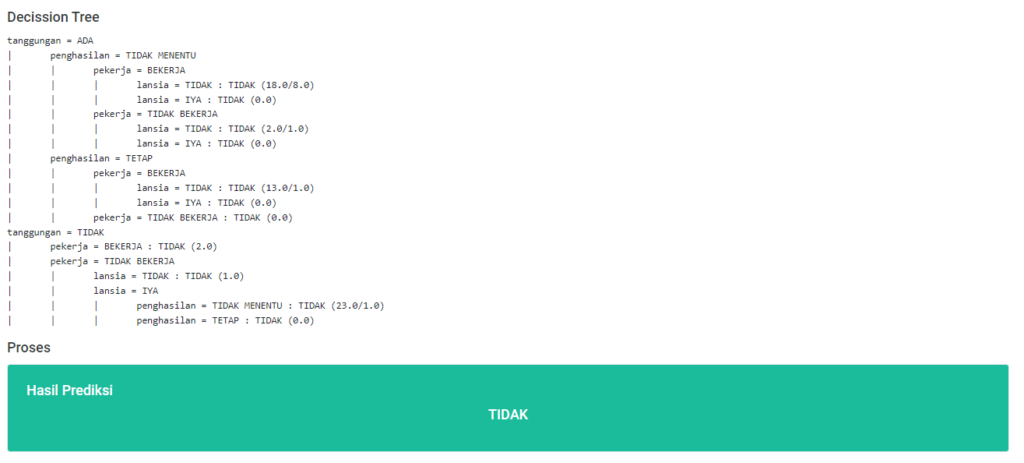
Tree Hasil Prediksi

Terdapat 3 tree yang di generate dari form prediksi, masing-masing tree dapat di klik, secara otomatis akan menampilkan drowdown anak2 pada tree nya seperti gambar diatas
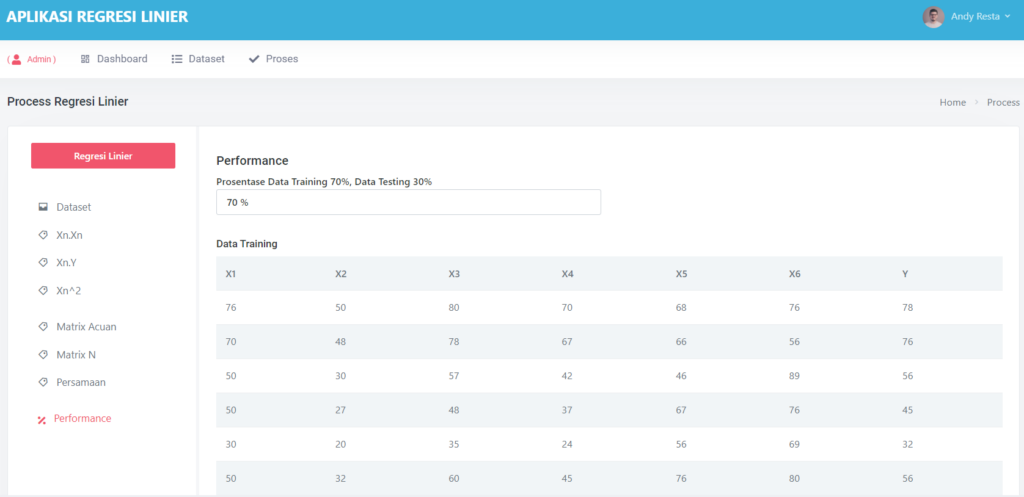
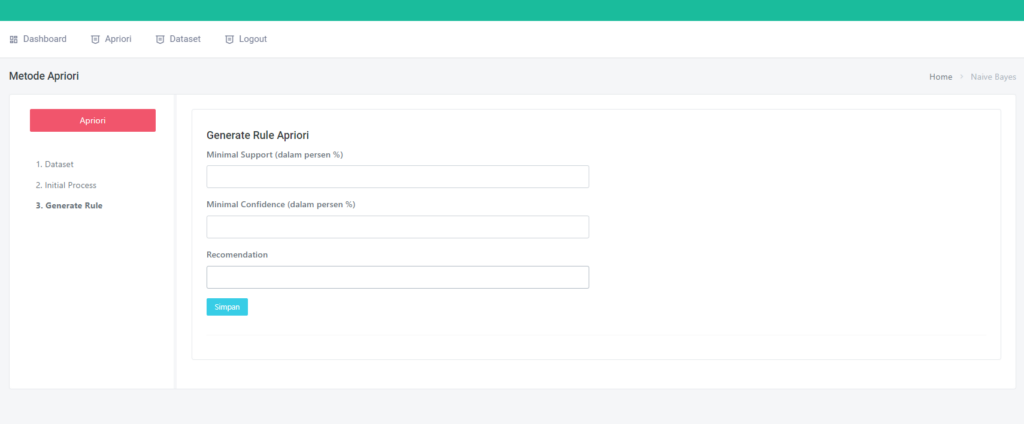
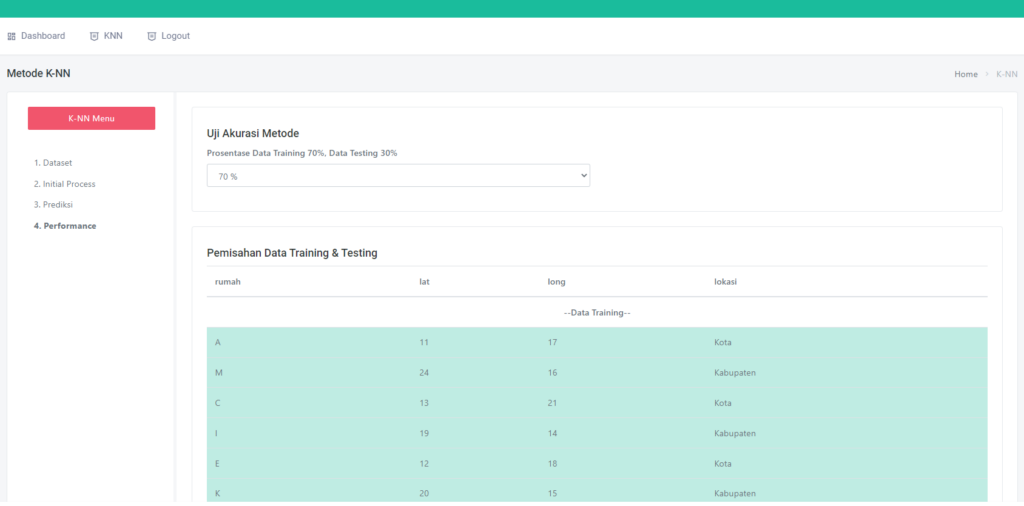
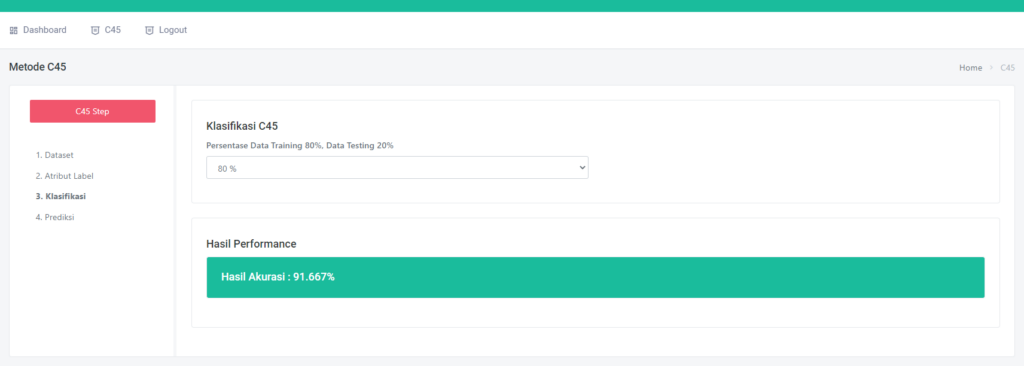
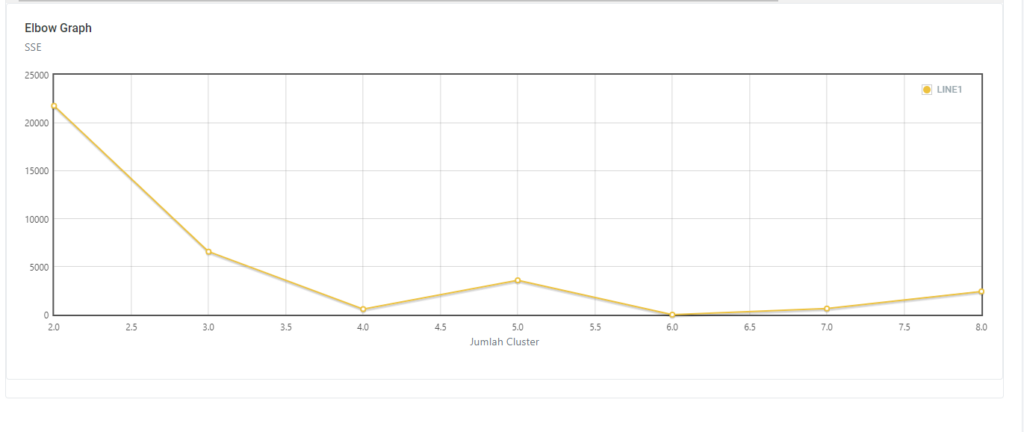
Halaman Performance Data Mining Random Forest
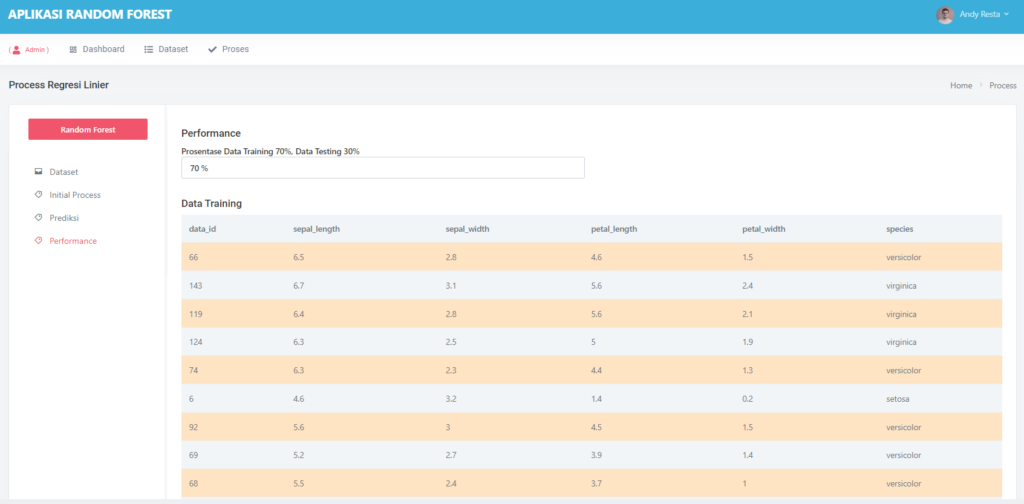

Halaman ini terdapat satu field inputan, yaitu prosentase. Jika kalian memilih prosentase 70% maka secara otomatis data akan dibagi menjadi 70% data training dan 30% data testing
Detail Data Training dan Testing dapat kalian lihat pada gambar diatas,
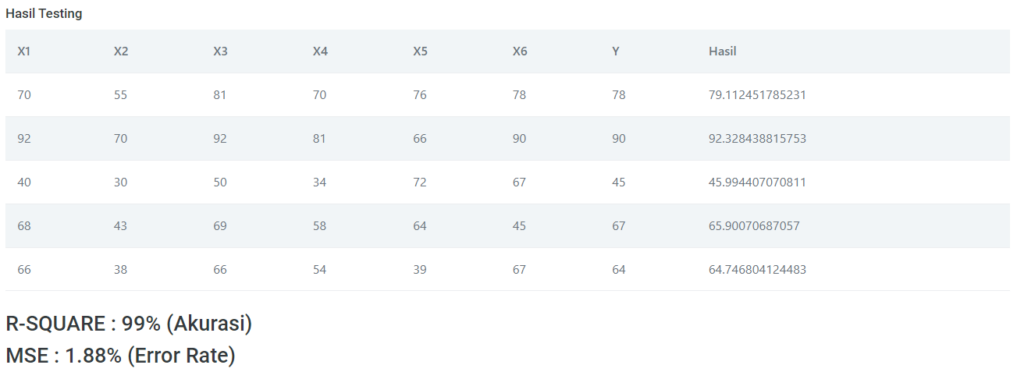
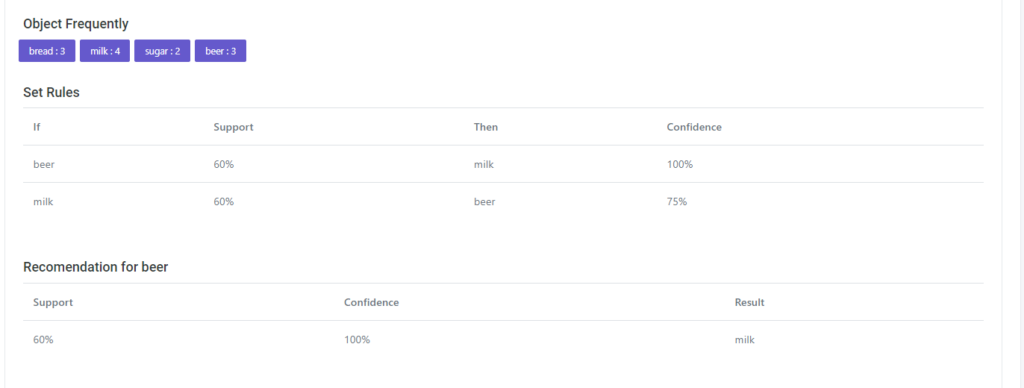
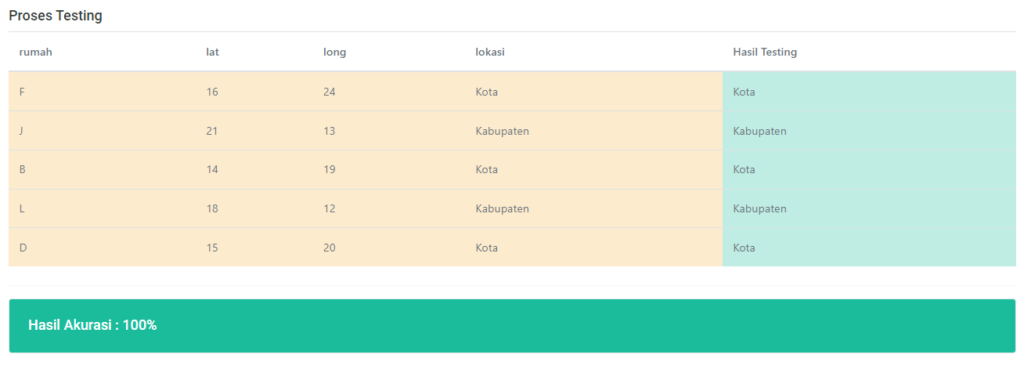
Hasil Performance

Jika kalian scroll kebawah akan menemukan hasil confussion matrix nya Akurasi, Presisi & Recall
Bagaimana Untuk Mendapat Aplikasinya ??
Jika anda tertarik & minat dengan aplikasi ini, atau anda ingin memodifikasi aplikasi ini bisa klik di tombol yang ada di bawah ini :
Cobalah kalian mendengar review kata-kata dari customer saya tentang aplikasi ini