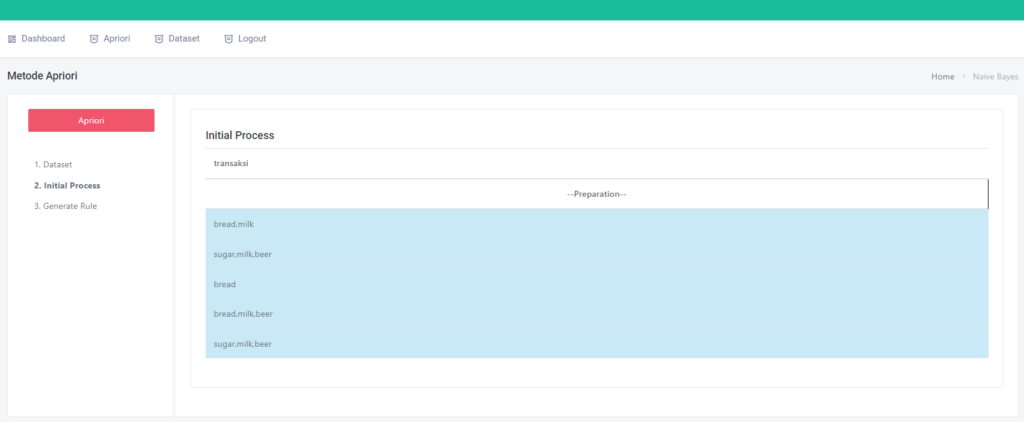
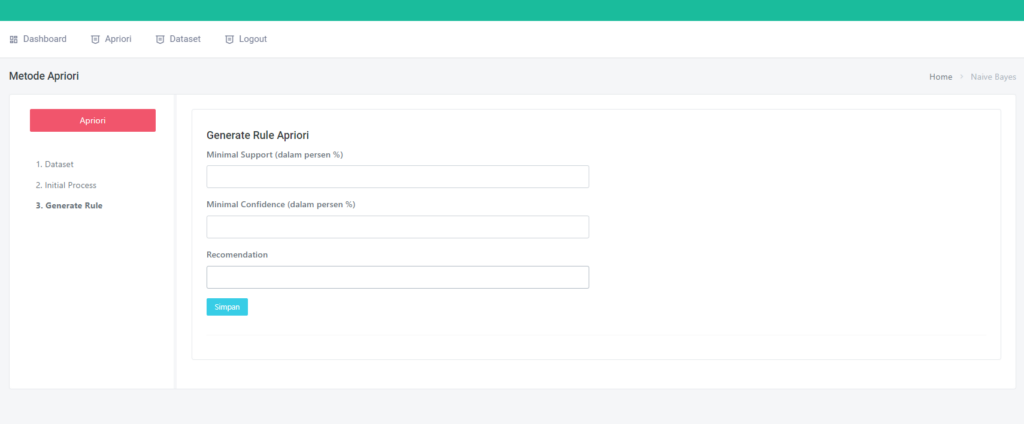
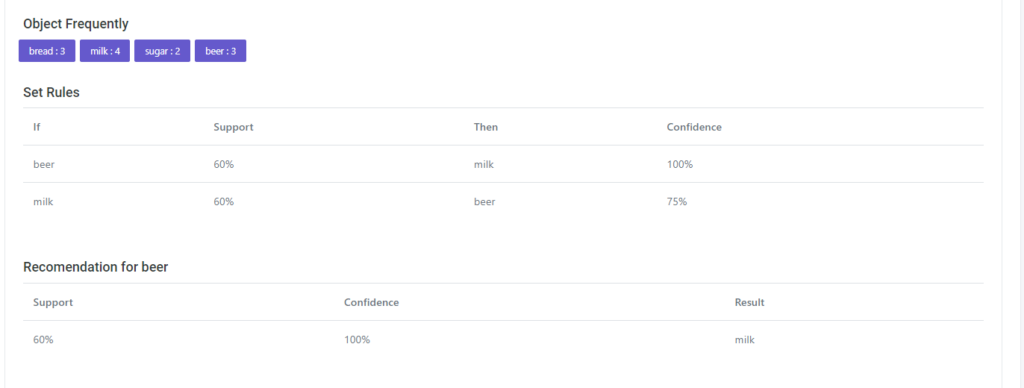
🔍 Pernah penasaran bagaimana cara kerja machine learning dari dalam?
Ingin melihat bagaimana algoritma belajar dari data dan membuat keputusan?
Kali ini, kita akan membedah secara langsung aplikasi web interaktif yang mengimplementasikan algoritma Perceptron, dibangun menggunakan PHP!
Cocok banget untuk pelajar, mahasiswa, dosen, maupun siapa saja yang ingin mempelajari dasar jaringan saraf tiruan tanpa harus coding dari nol.
Apa Itu Perceptron?
Sederhananya, Perceptron adalah algoritma pembelajaran mesin paling dasar yang digunakan untuk menyelesaikan masalah klasifikasi biner. Misalnya: menentukan apakah sebuah email adalah spam atau bukan.
Prinsip kerjanya seperti ini:
- Input dikalikan dengan bobot.
- Dijumlahkan dan dilewatkan ke fungsi aktivasi (biasanya sigmoid).
- Hasilnya dibandingkan dengan threshold, lalu ditentukan kelasnya.
Dan semua proses itu… bisa kamu lihat langsung lewat aplikasi yang akan kita bahas ini!
👨💻 Tampilan Dashboard: Simpel Tapi Powerful
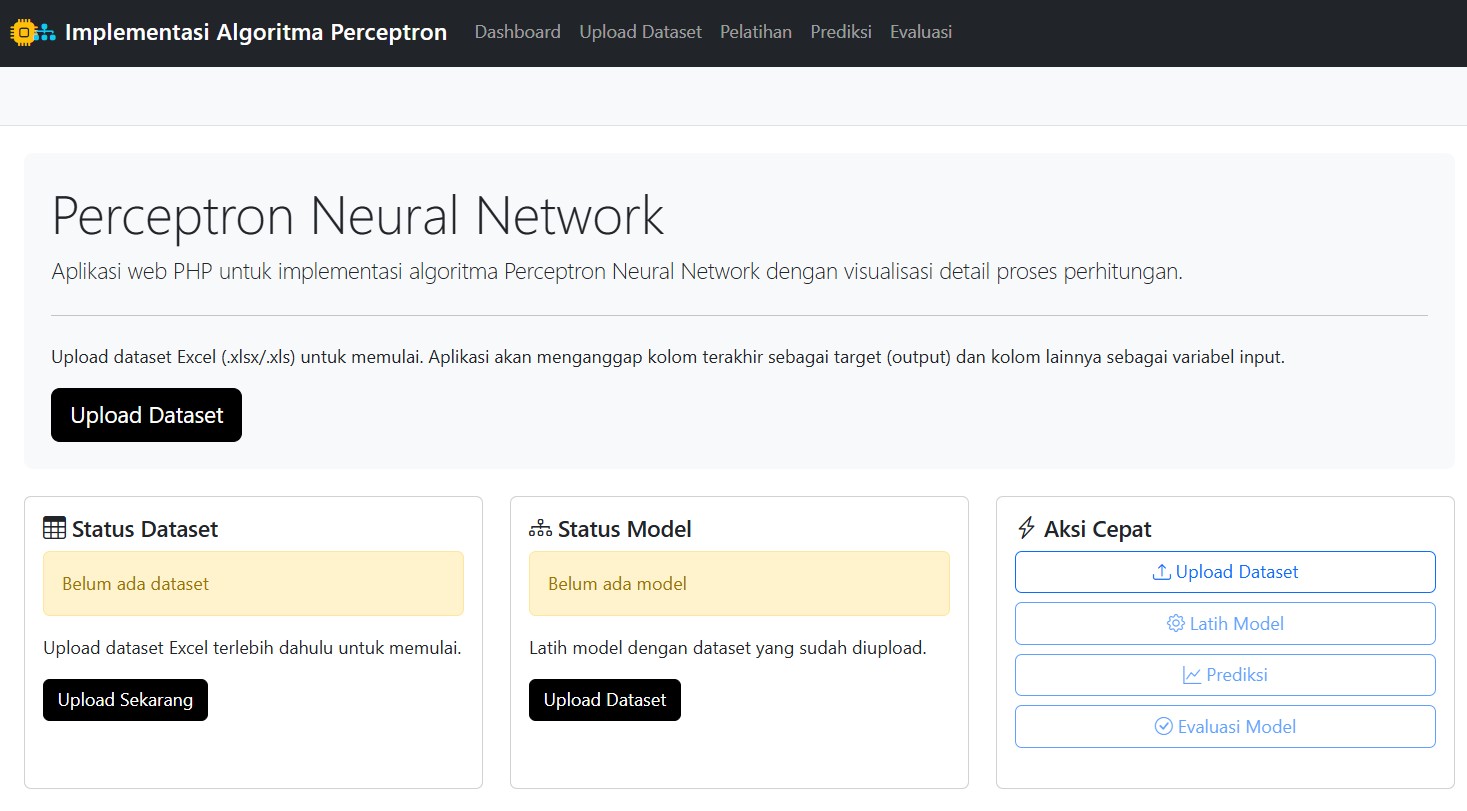
Setelah aplikasi dibuka, kamu akan disambut oleh tampilan dashboard yang bersih dan rapi.
Tersedia navigasi untuk semua fitur penting: Upload Dataset, Pelatihan, Prediksi, dan Evaluasi.
Di sinilah perjalanan pembelajaran kita dimulai.
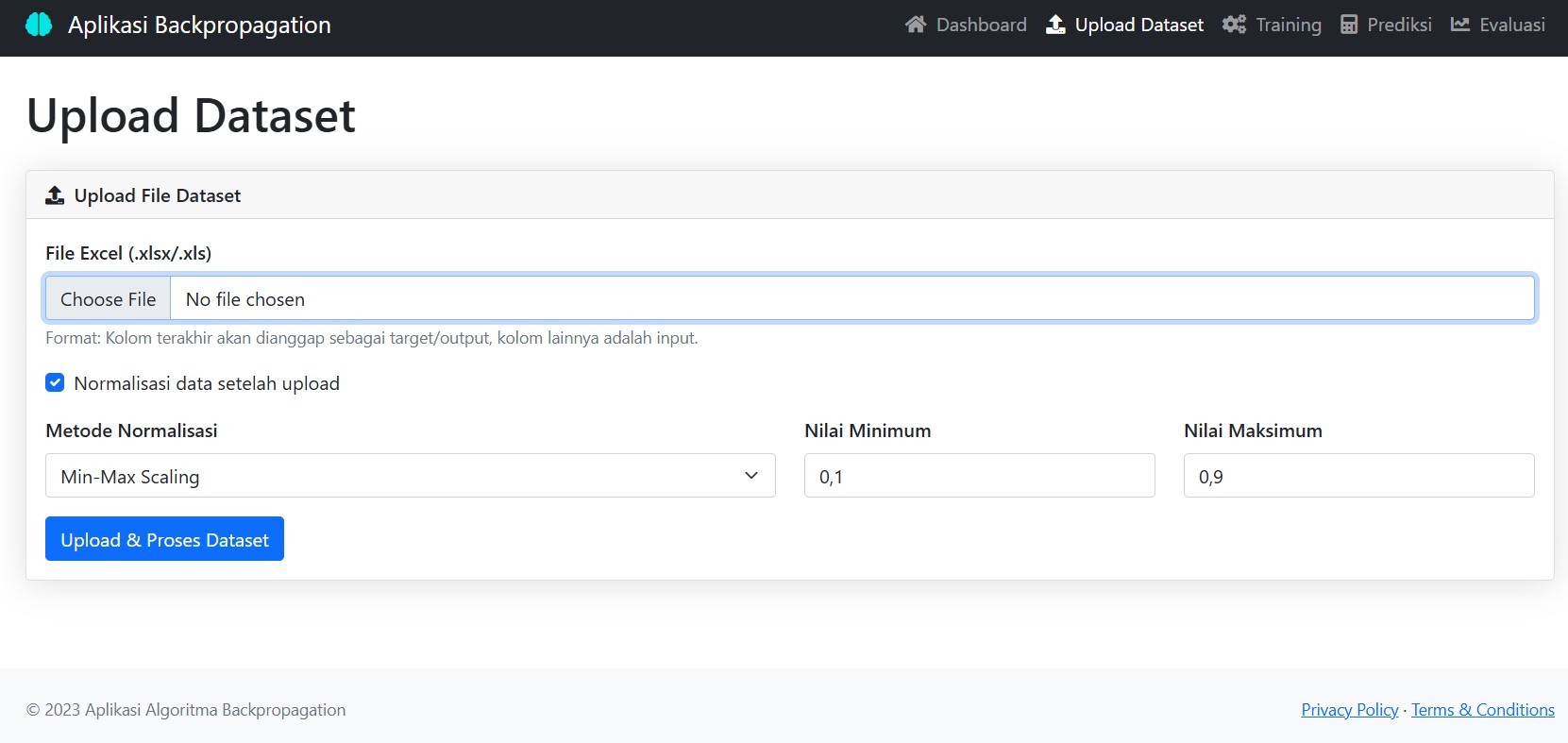
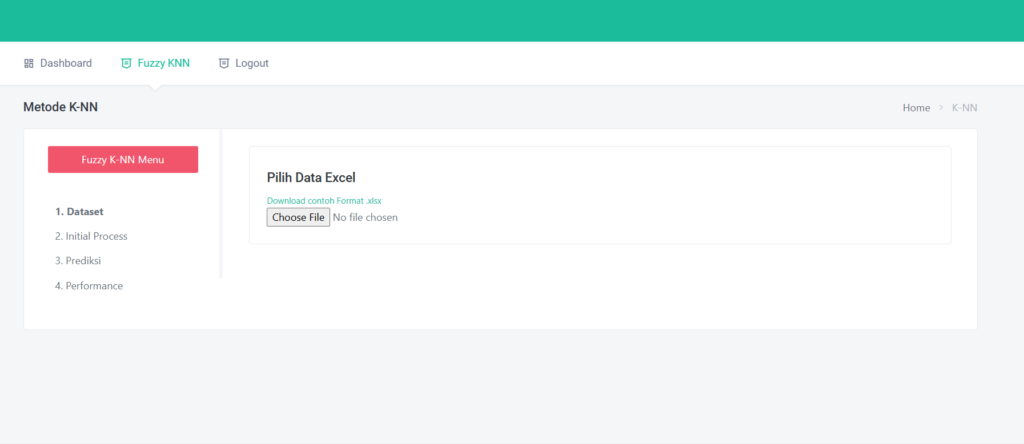
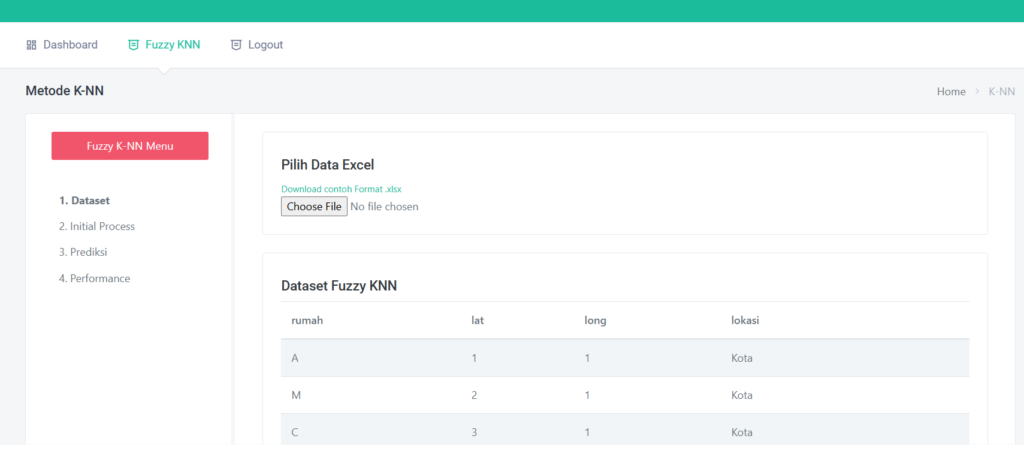
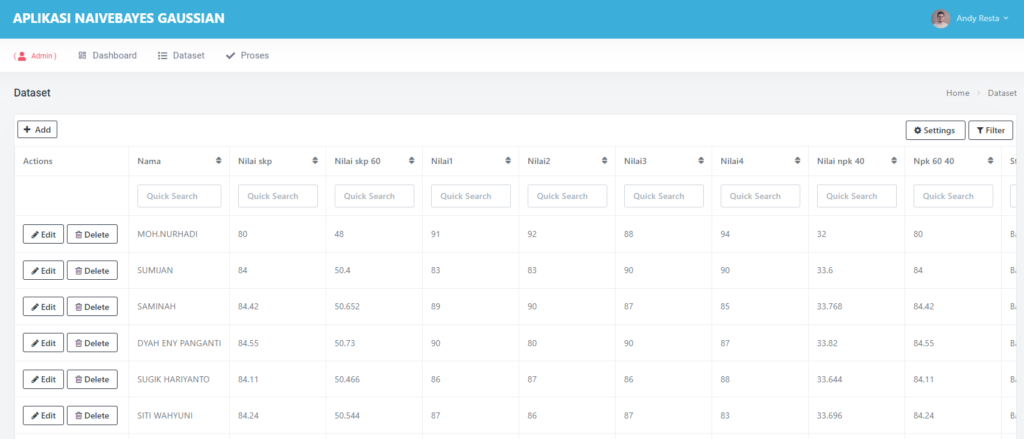
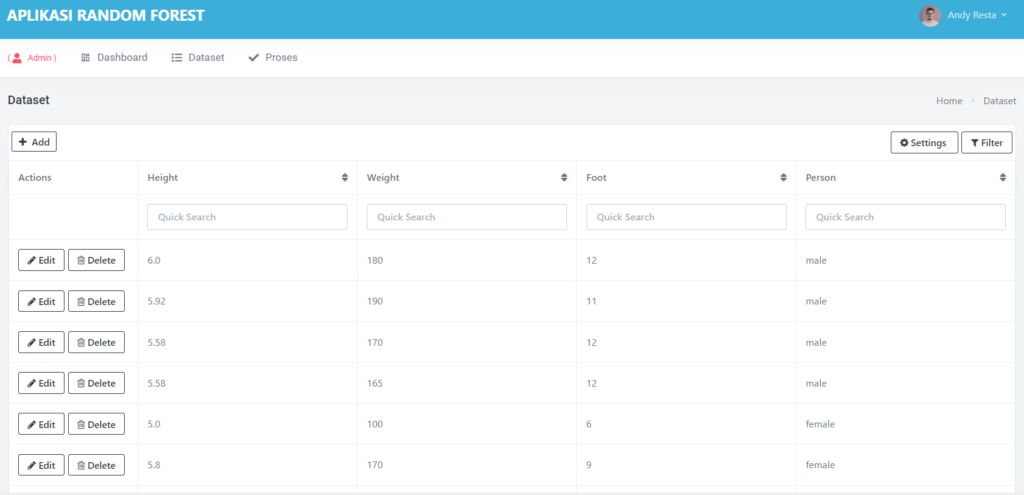
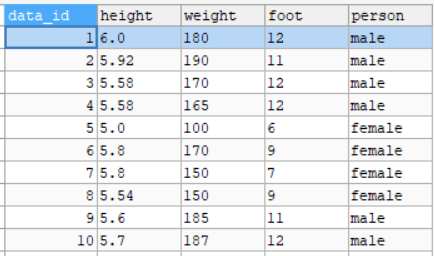
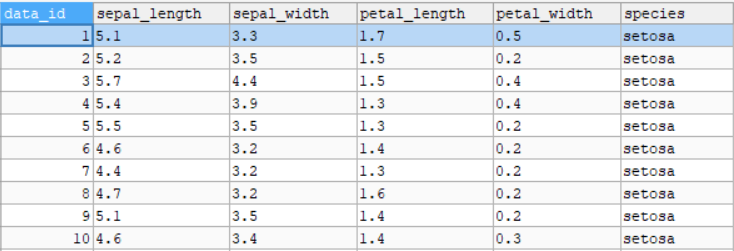
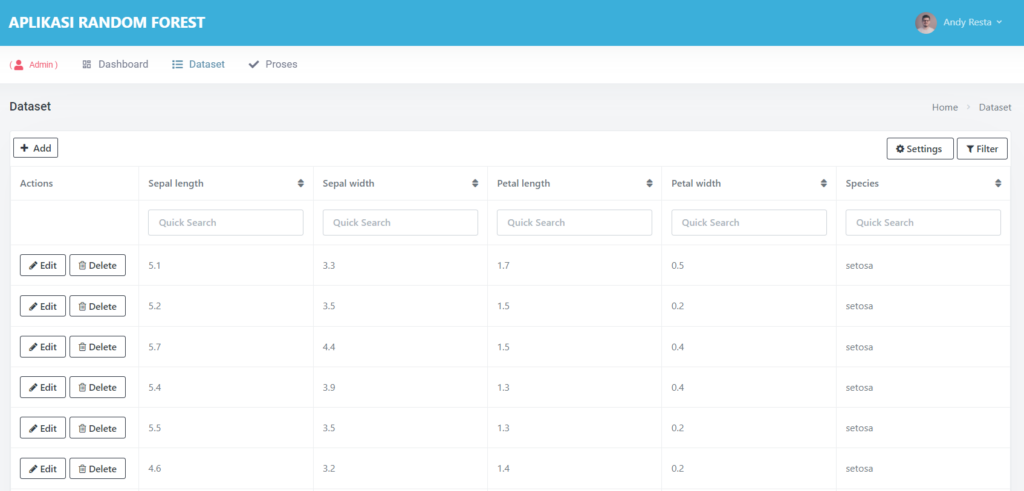
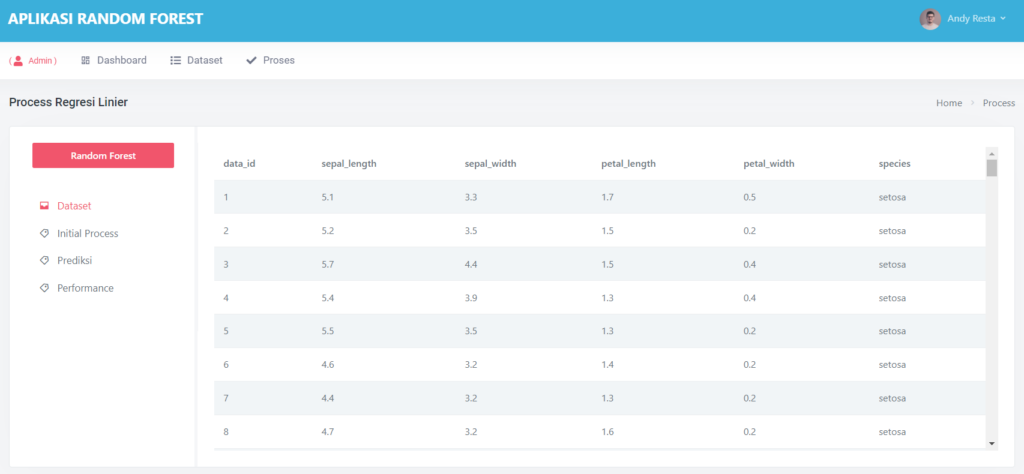
📂 Upload Dataset: Cukup Satu Klik
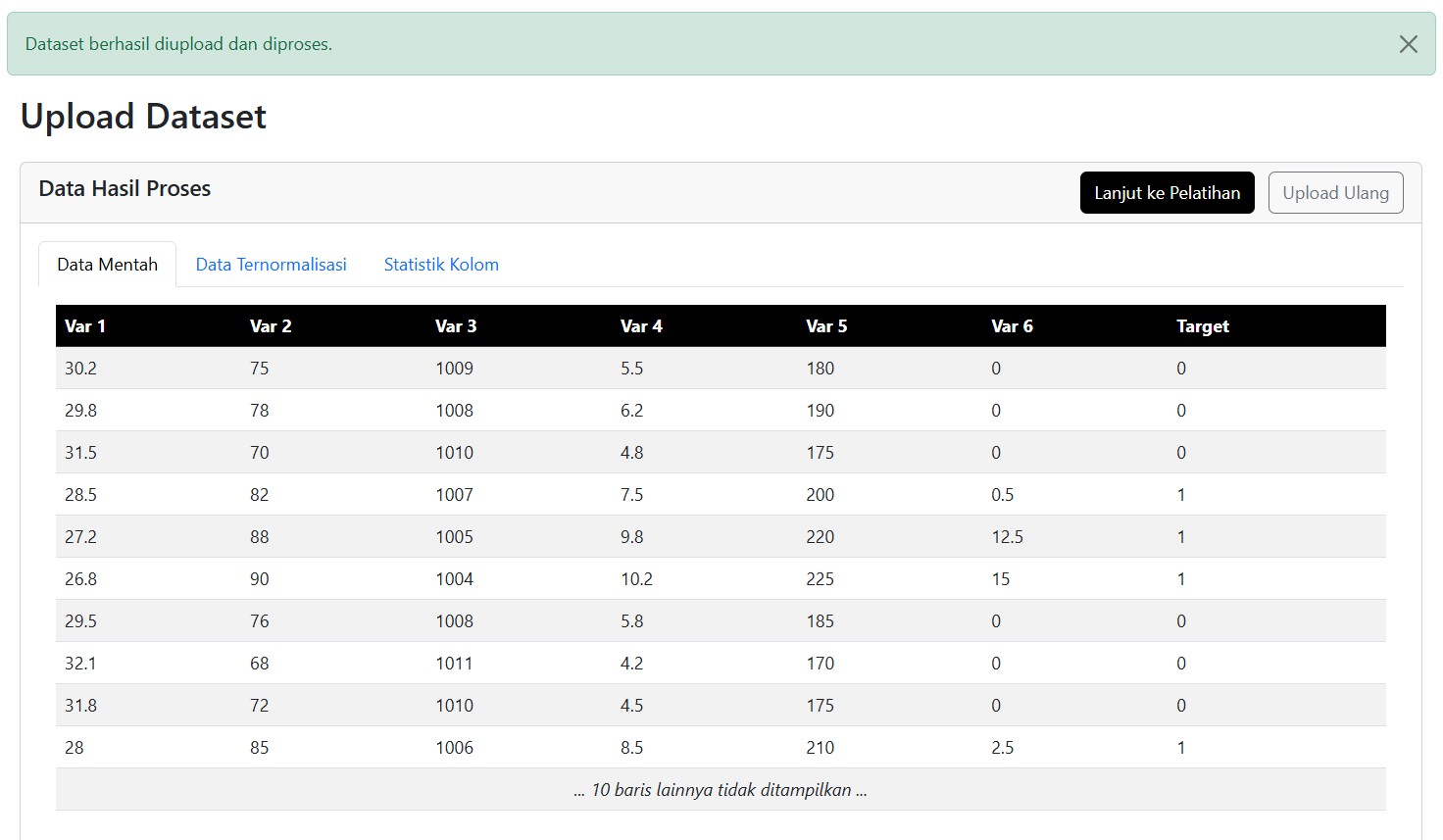
Kamu hanya perlu mengunggah file Excel (.xls atau .xlsx) dengan format sederhana.
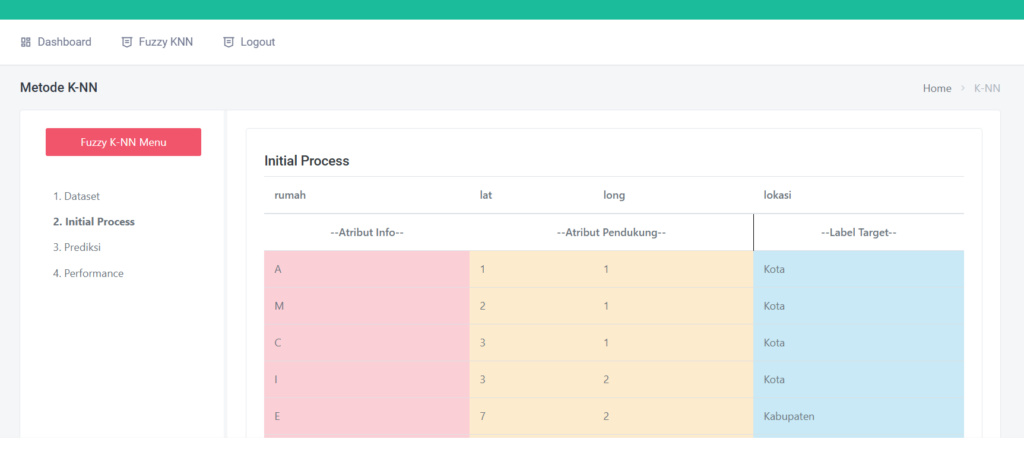
Aplikasi ini secara otomatis akan mengenali kolom terakhir sebagai target/output, dan sisanya sebagai input.
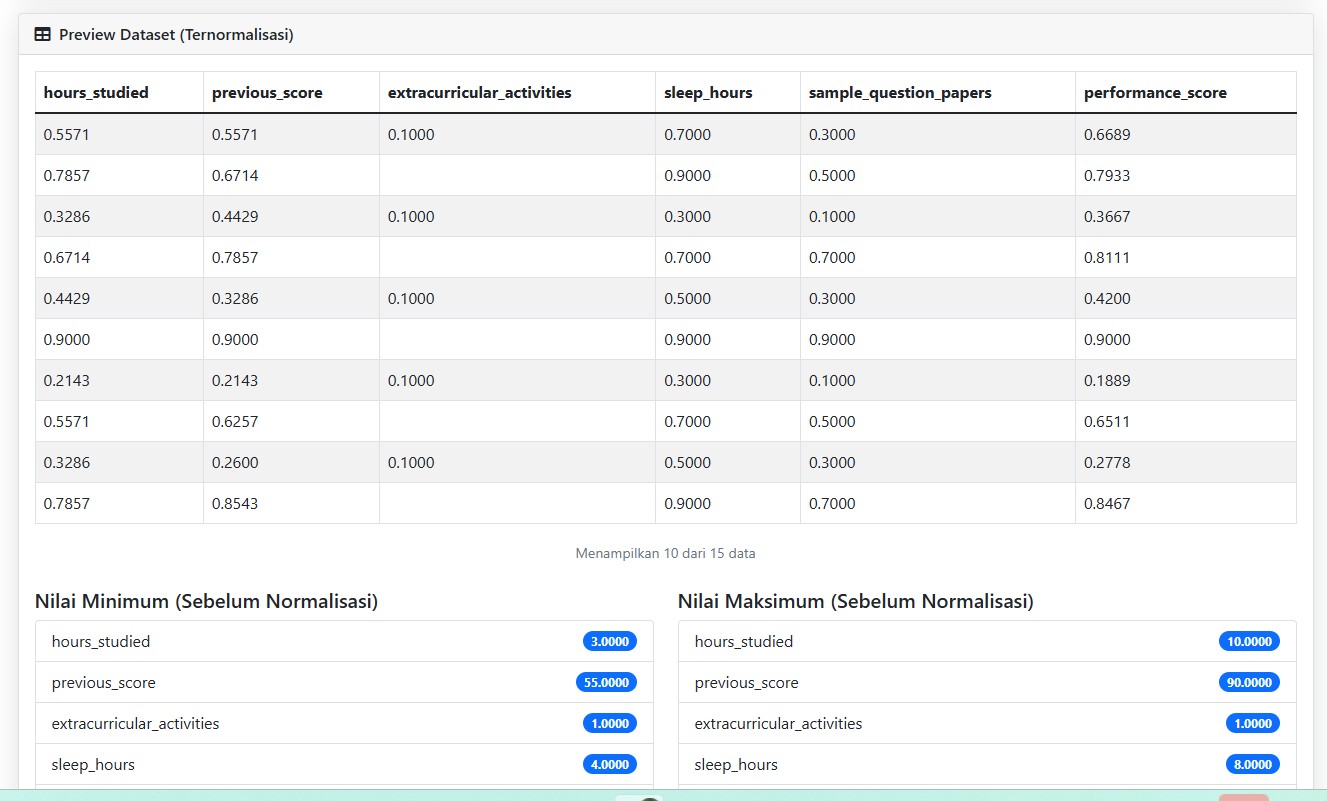
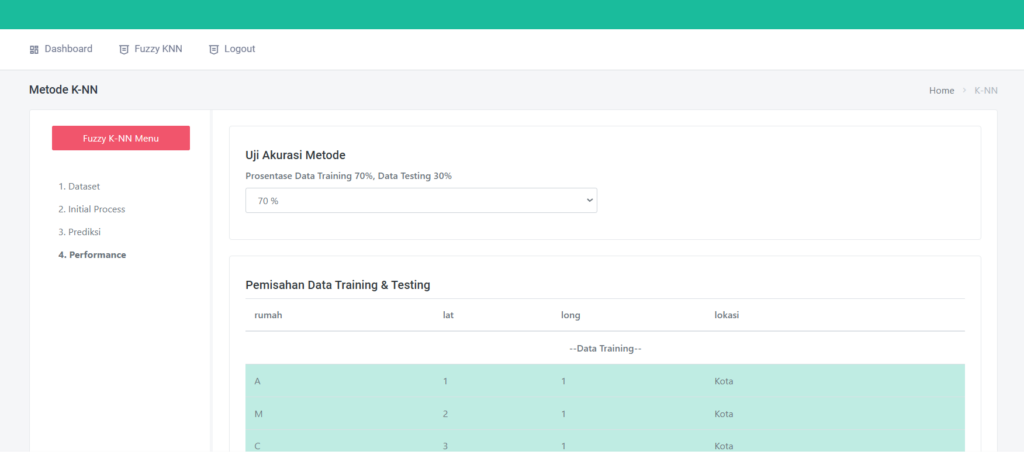
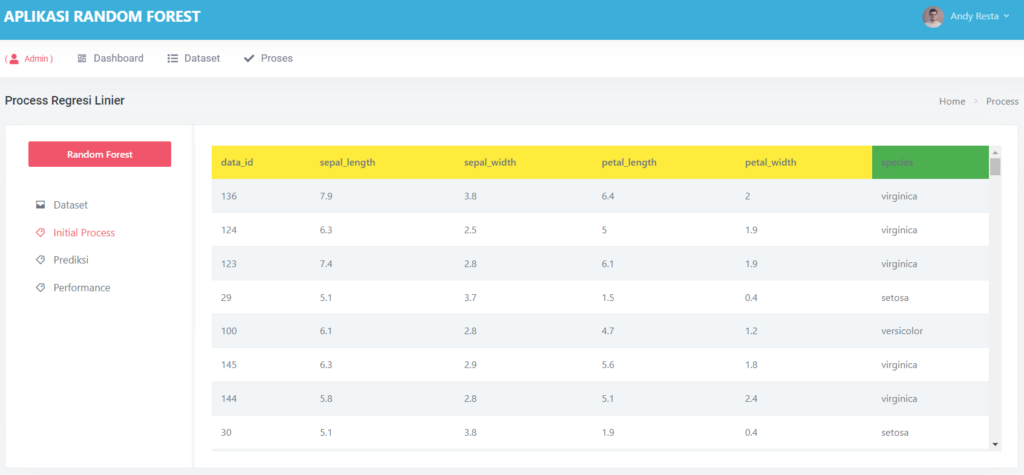
Begitu file diunggah, data langsung ditampilkan dalam tiga bentuk:
- Data Mentah (raw)
- Data yang Ternormalisasi
- Statistik Kolom
➡️ Tidak perlu repot dengan preprocessing manual!
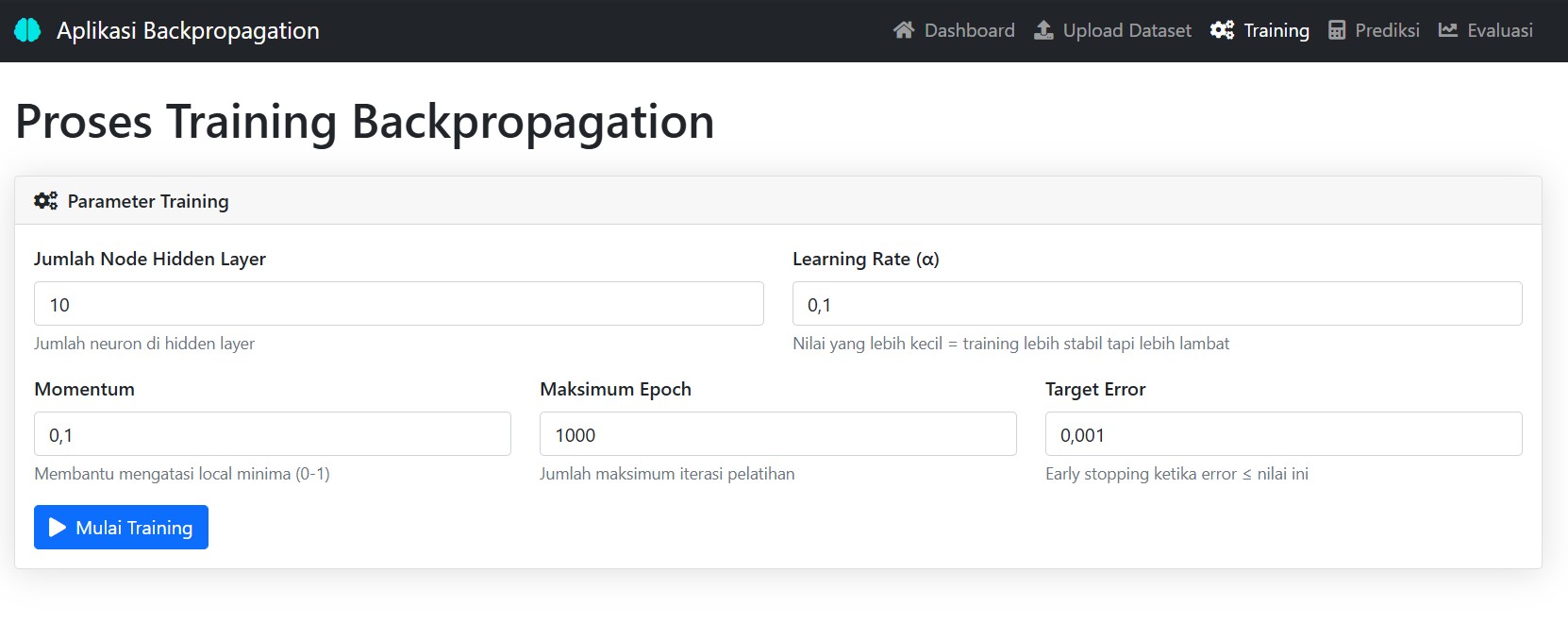
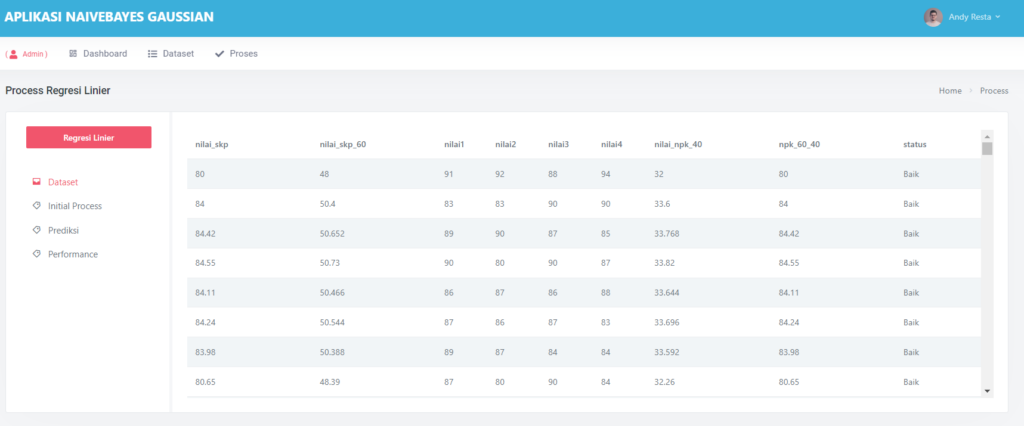
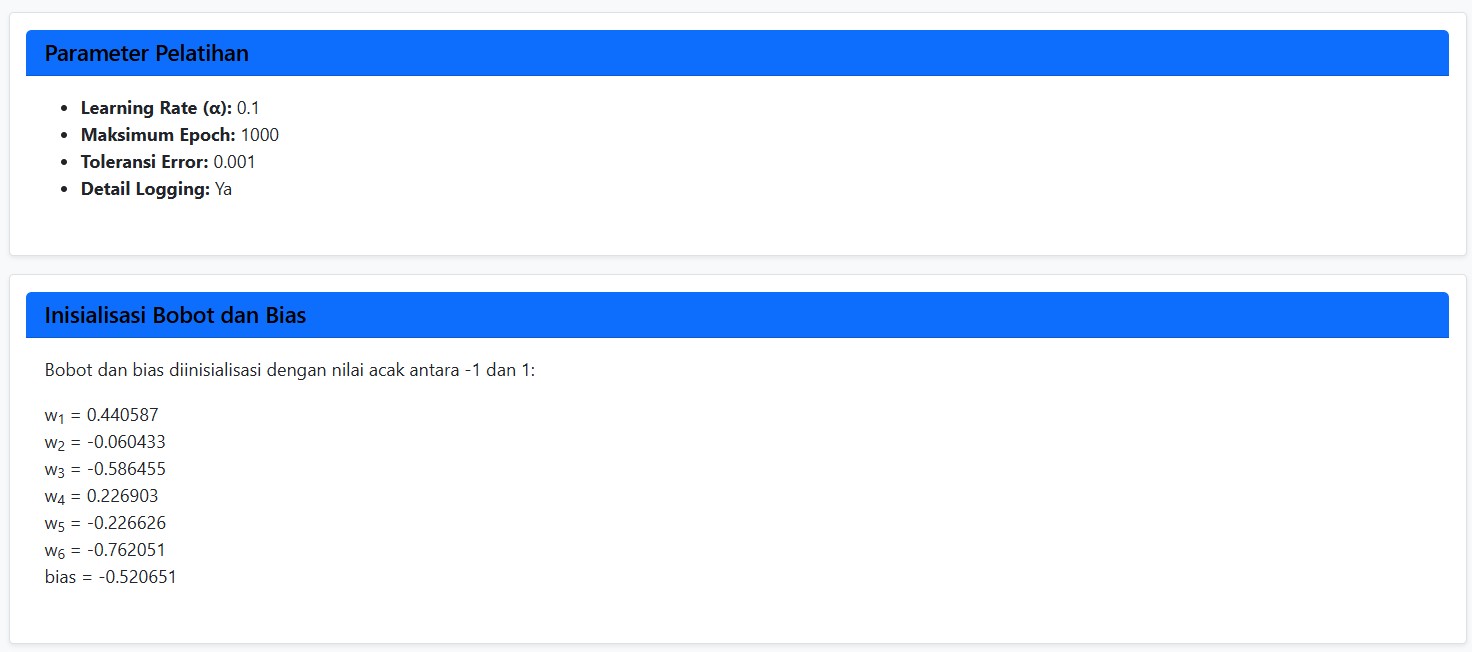
⚙️ Pelatihan Model: Atur Sendiri Parameter Pembelajaran
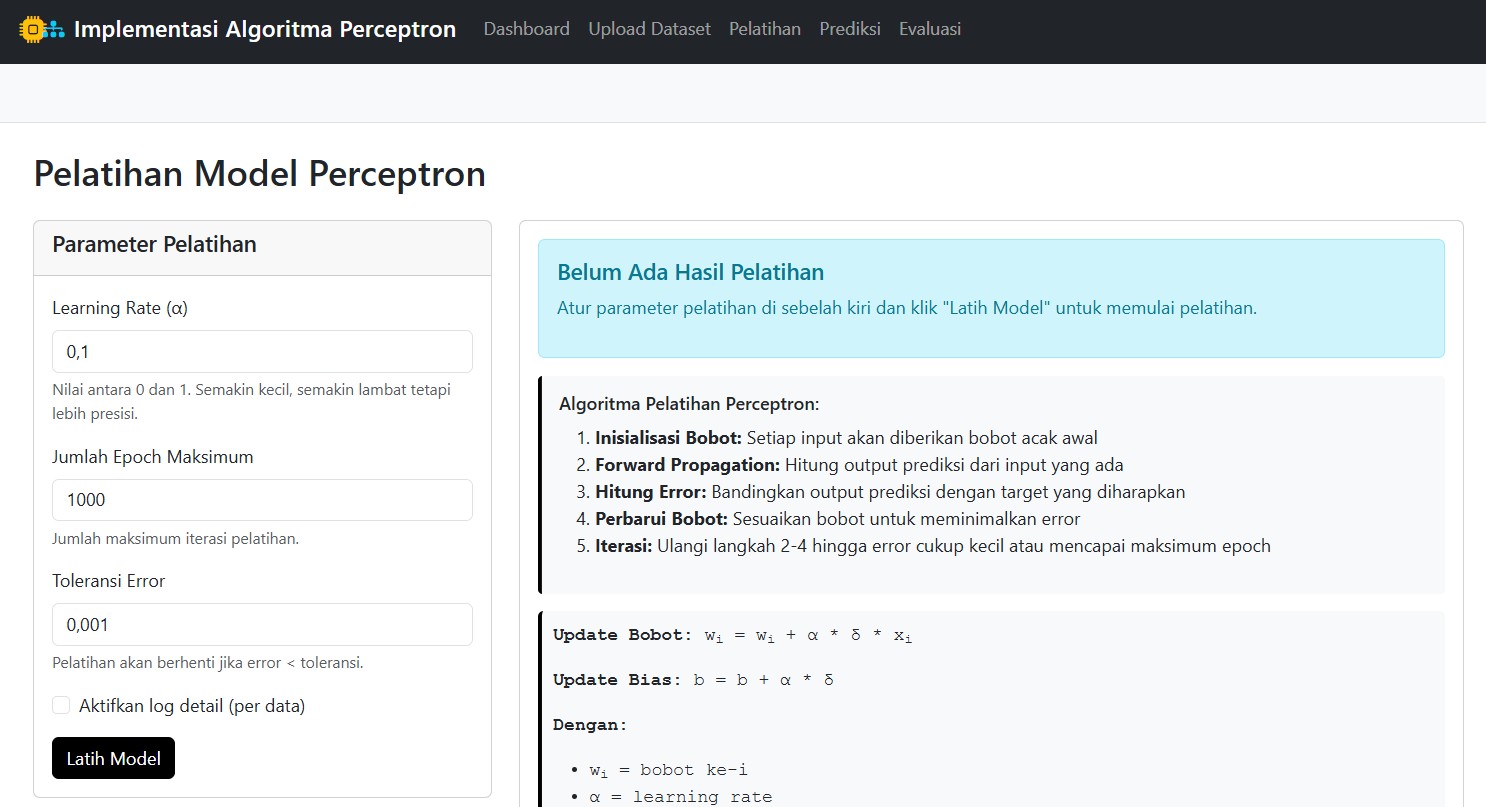
Inilah jantung dari aplikasi ini.
Kamu bisa mengatur:
- Learning rate: Seberapa cepat model belajar
- Jumlah epoch: Berapa kali data diulang untuk melatih model
- Toleransi error: Kapan pelatihan dianggap cukup
Setelah itu, tinggal klik “Latih Model”, dan proses pembelajaran dimulai!
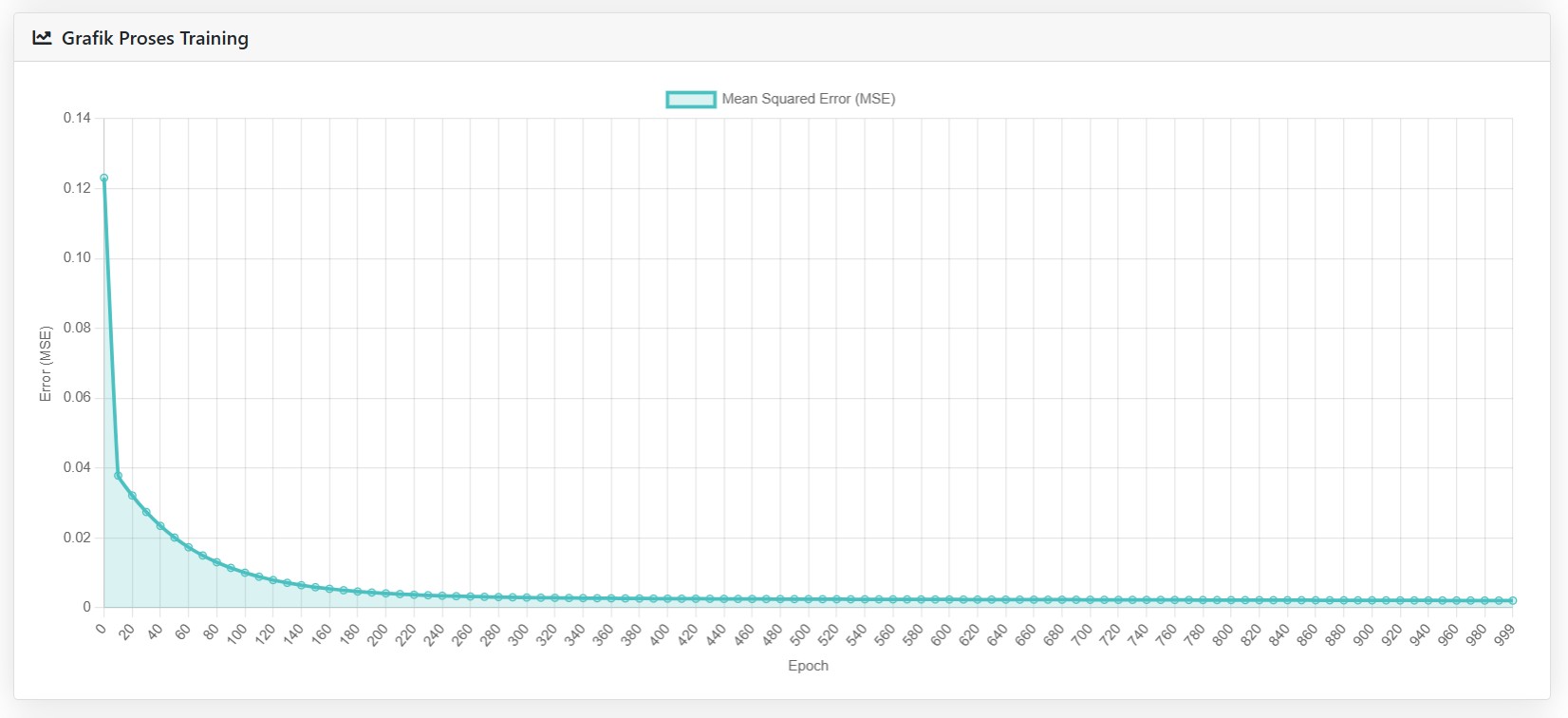
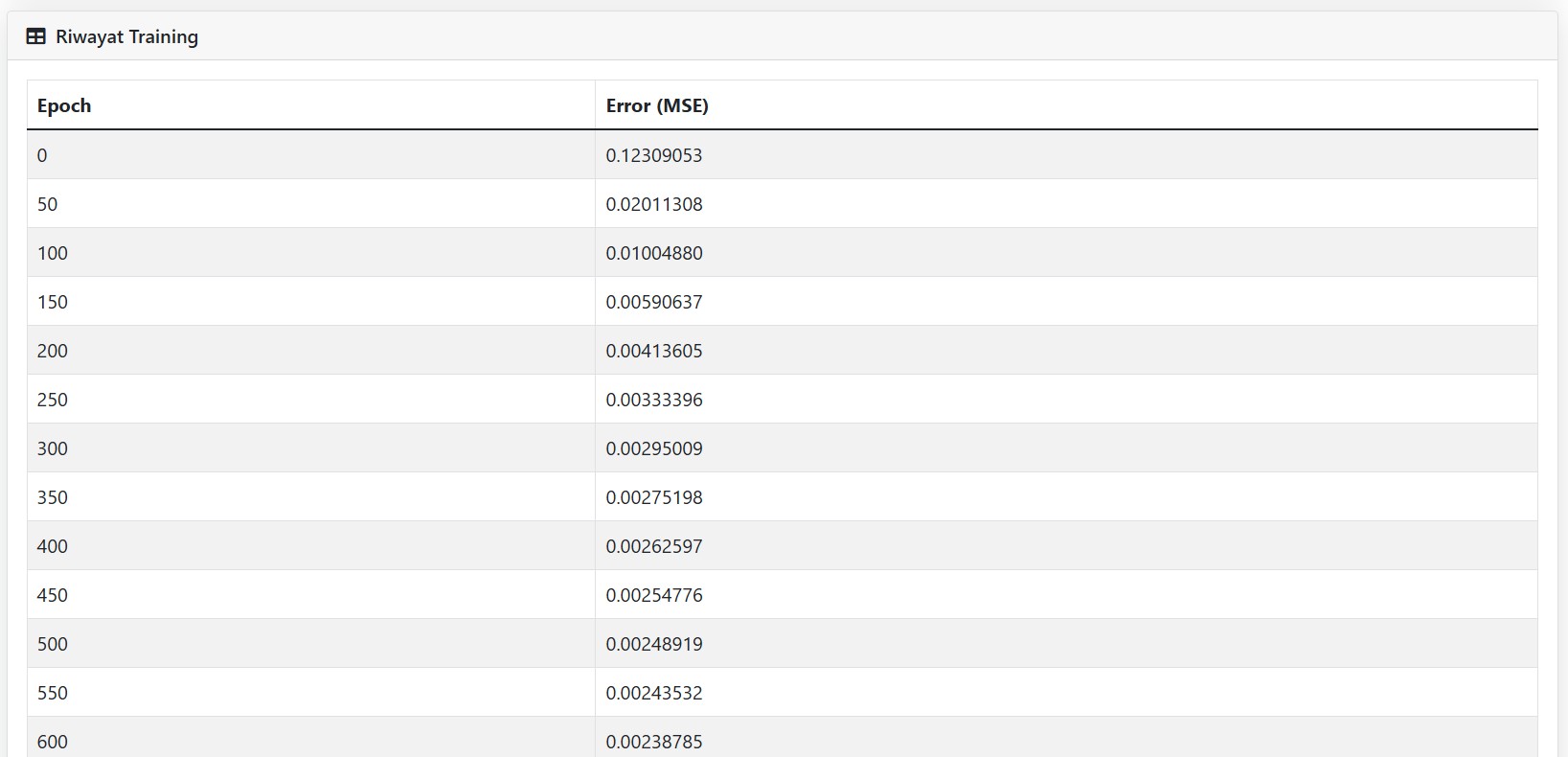
📈 Visualisasi Error & Detail Iterasi
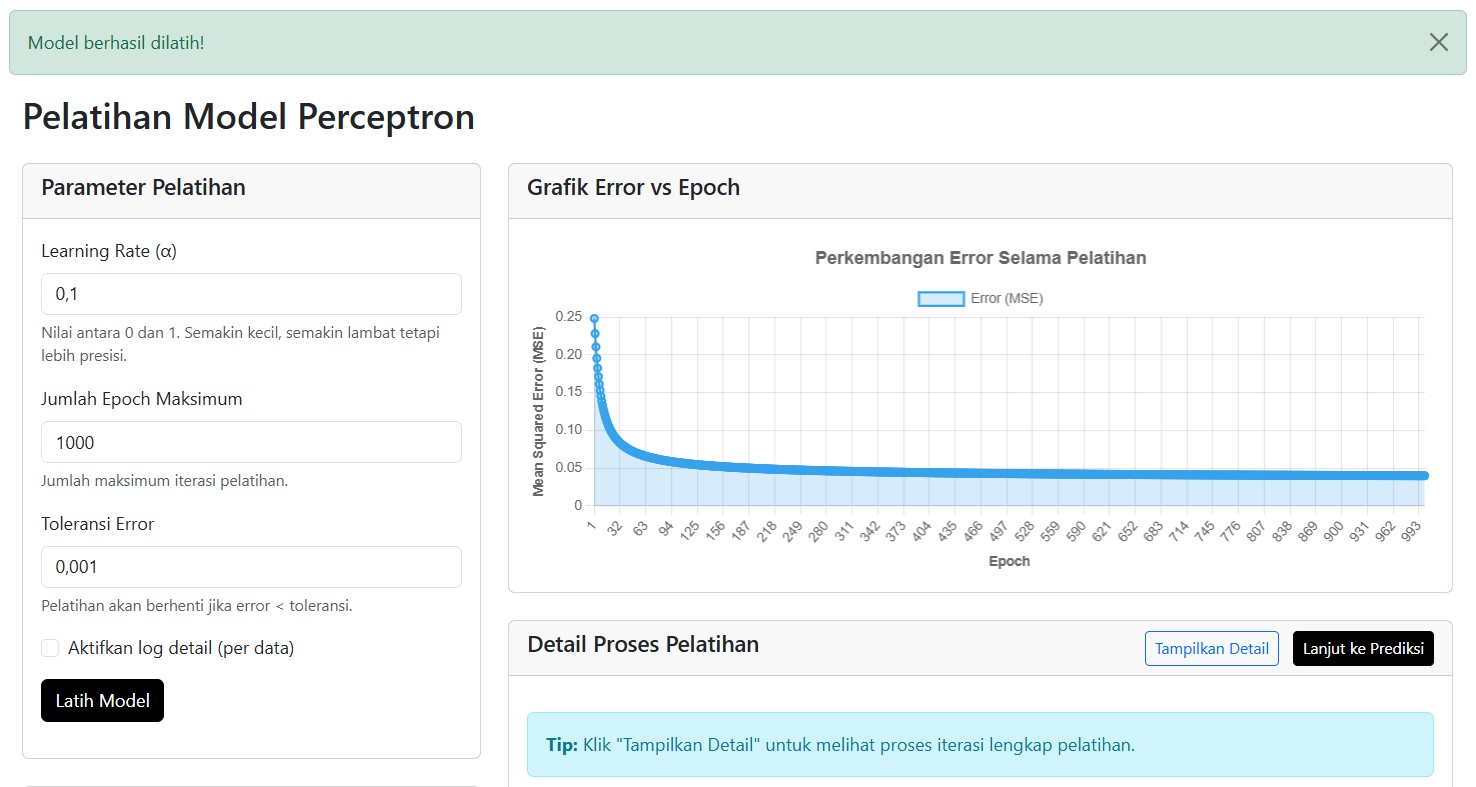
Yang menarik: aplikasi ini tidak hanya memberi hasil akhir, tapi juga memvisualisasikan perjalanan model belajar.
- Grafik Error vs Epoch menunjukkan seberapa cepat model belajar.
- Ada log detail untuk melihat setiap iterasi, perubahan bobot, dan hasil prediksi.
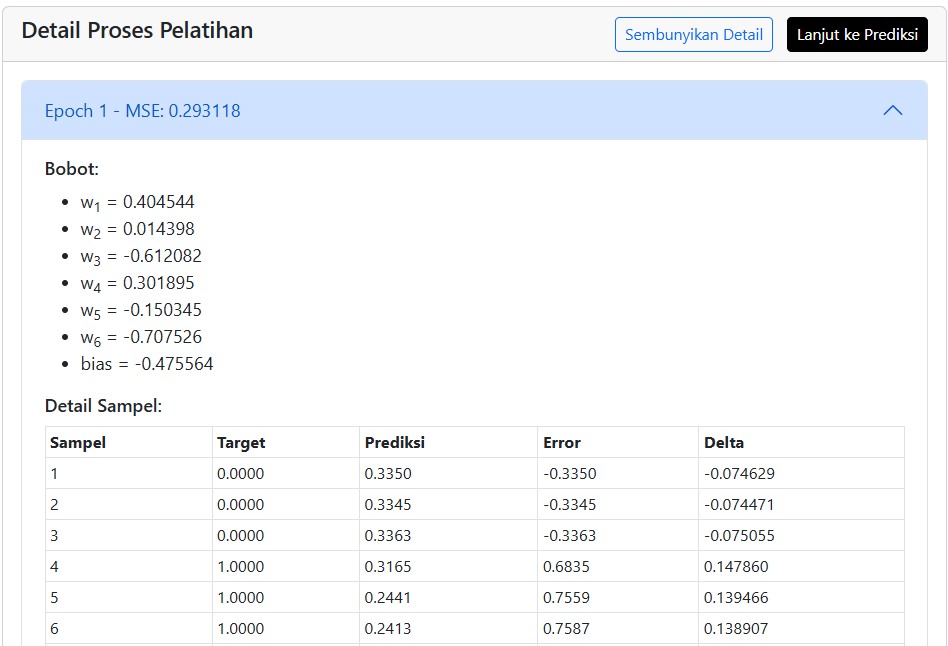
Kita bisa melihat bagaimana error perlahan menurun… hingga akhirnya stabil.
Pengalaman belajar yang tidak hanya praktis, tapi juga menyenangkan!
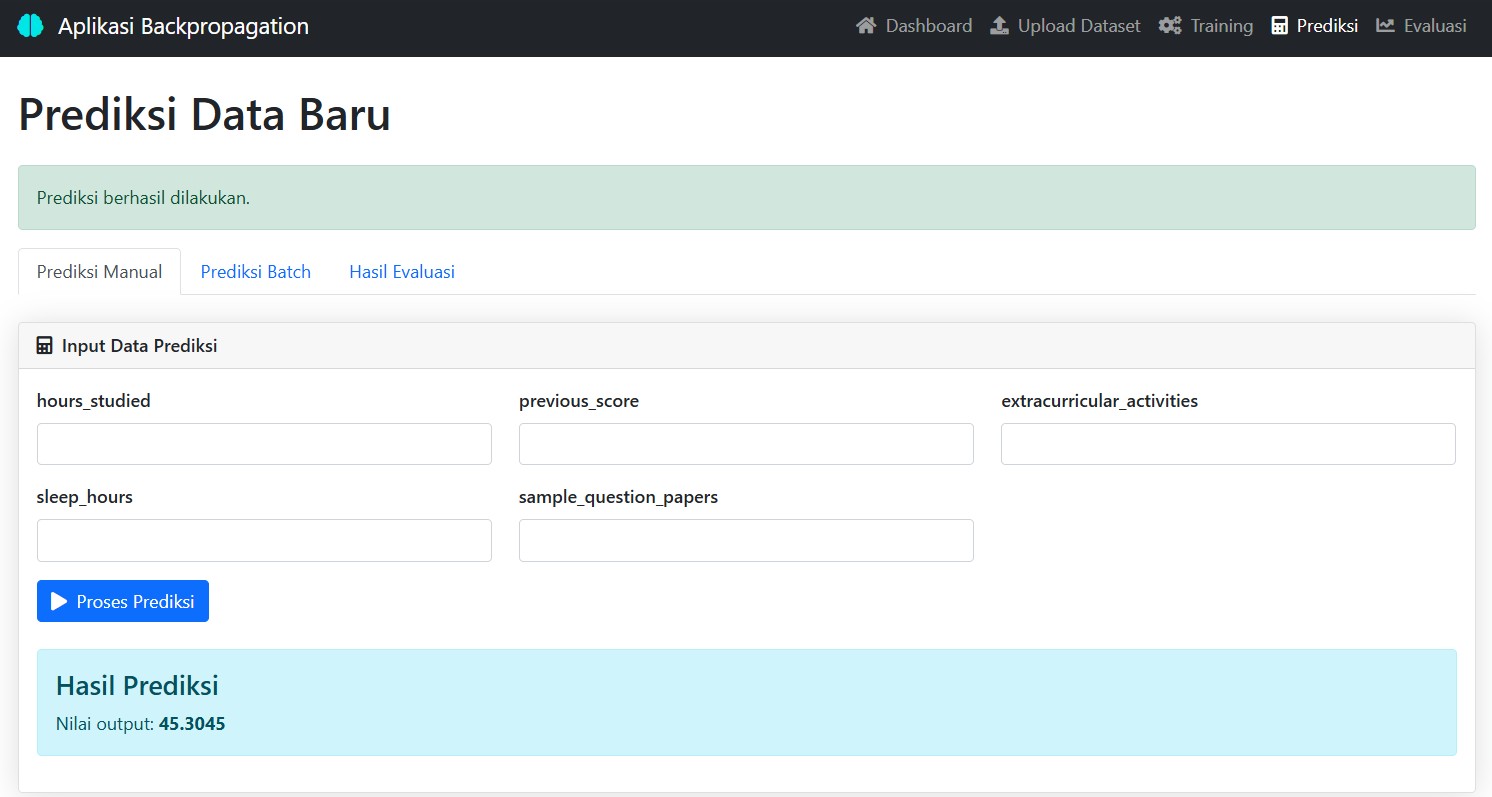
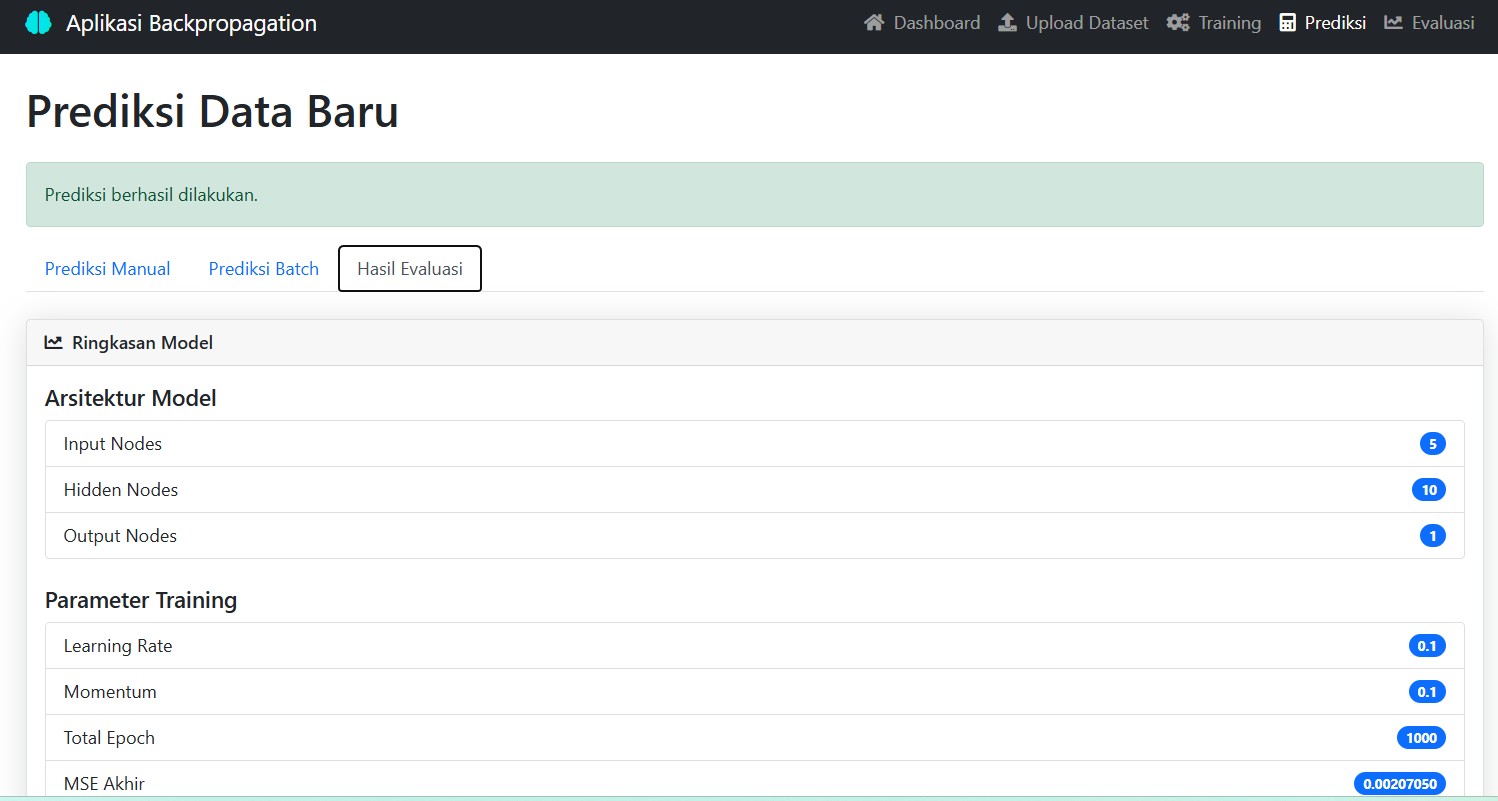
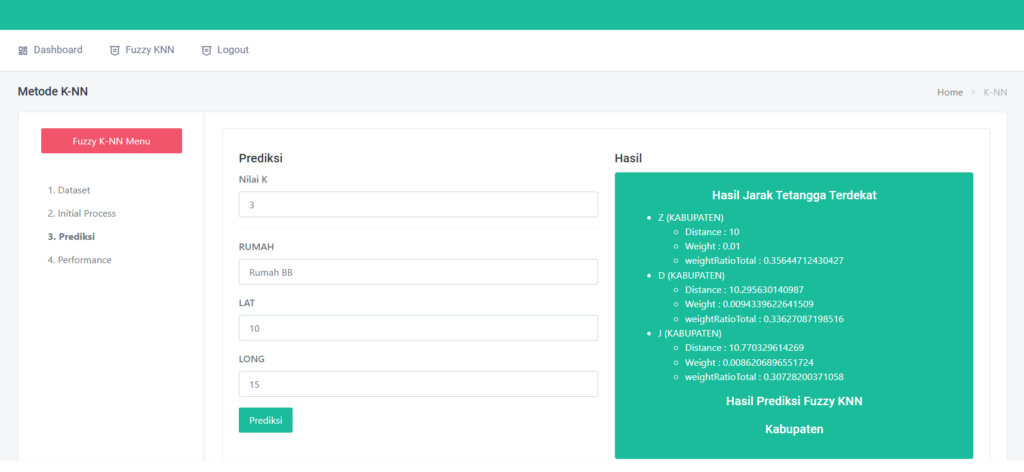
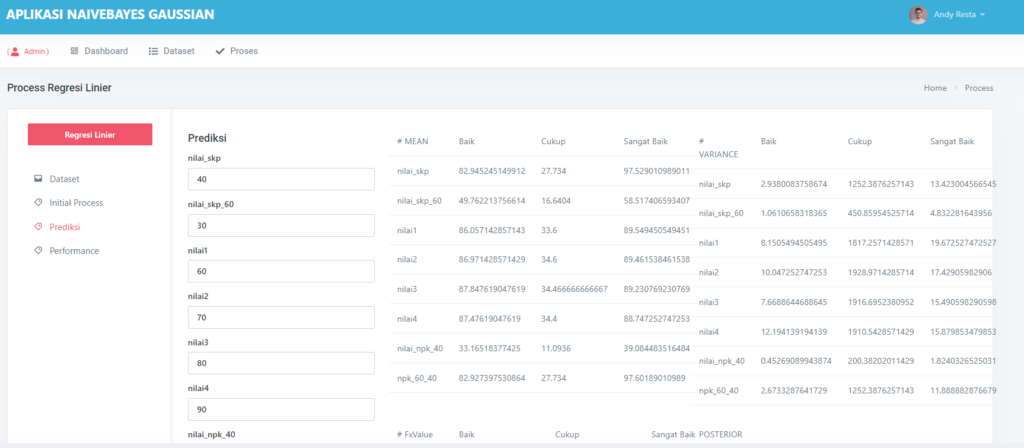
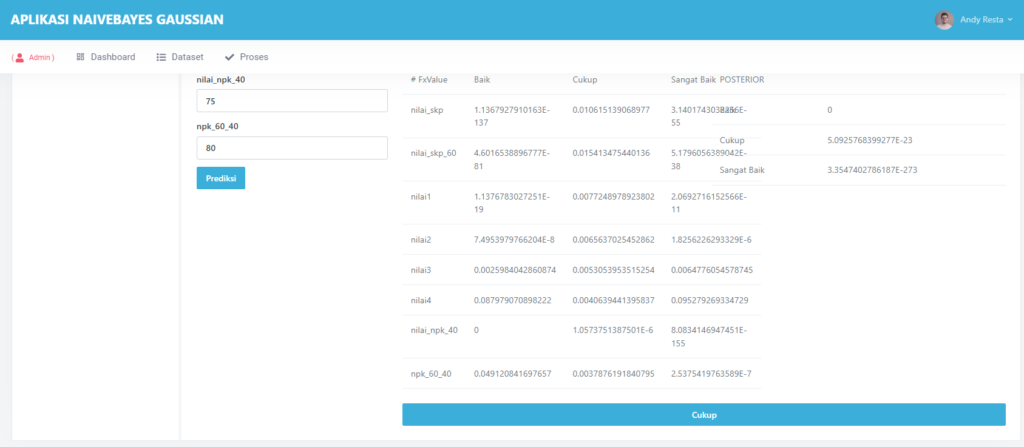
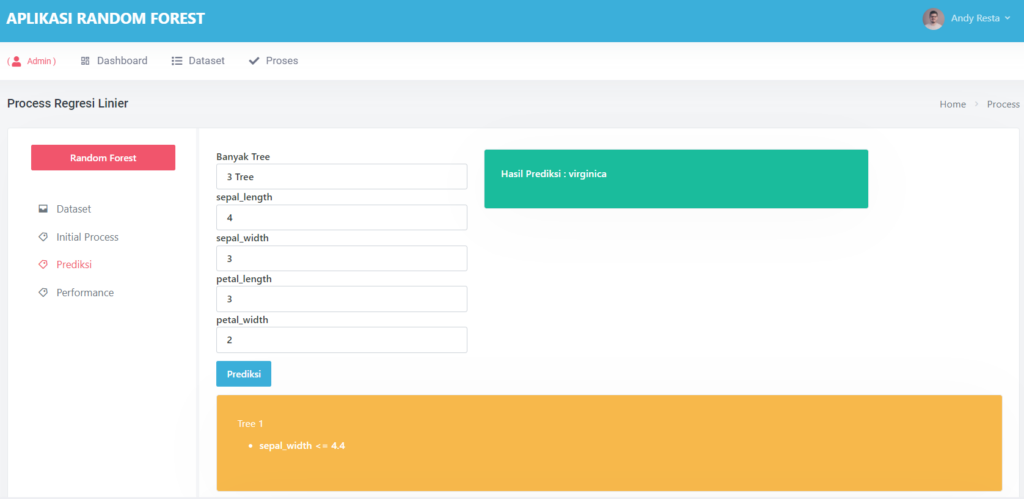
🤖 Prediksi: Coba Sendiri Model yang Sudah Dilatih
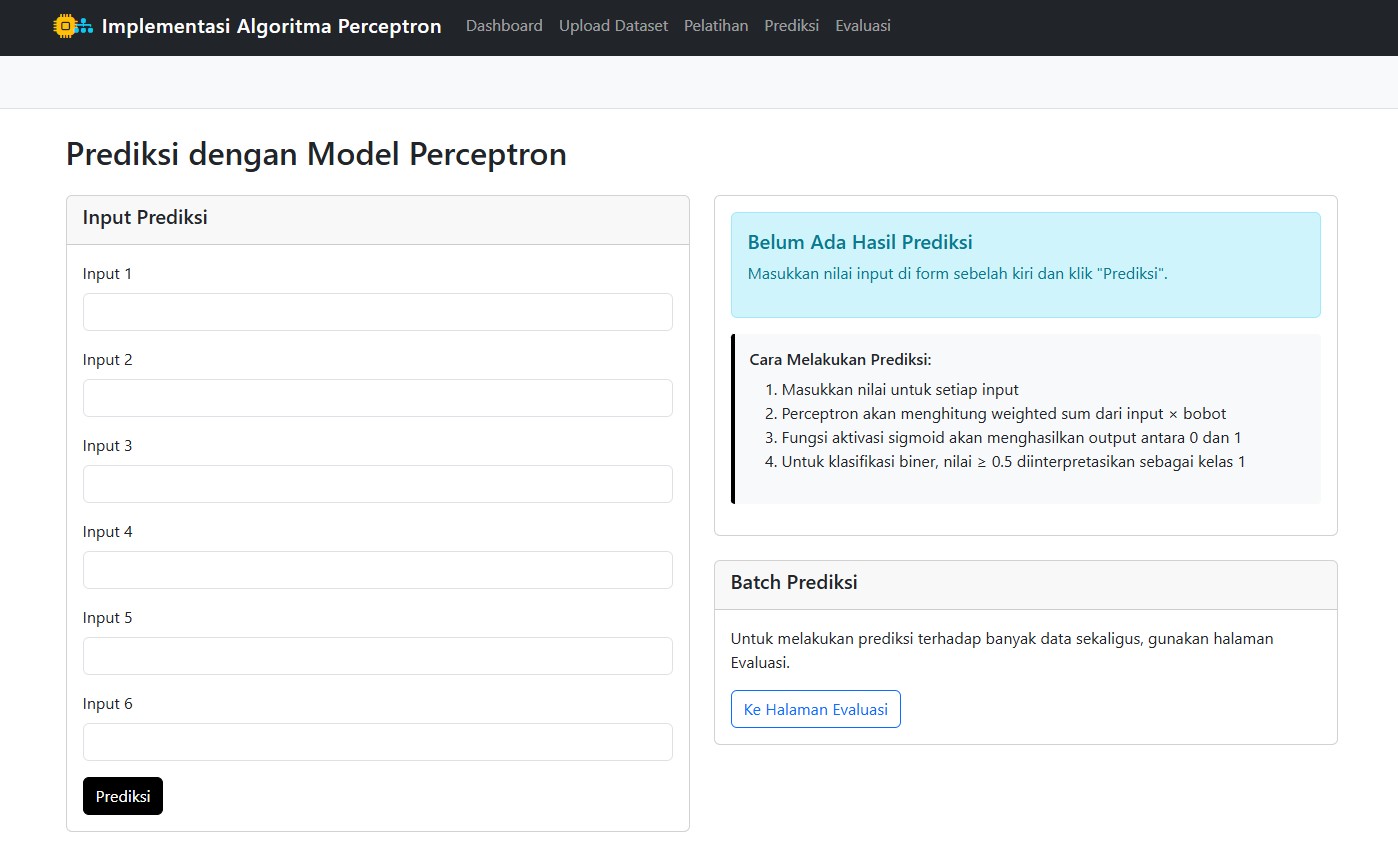
Setelah pelatihan selesai, kamu bisa langsung menguji model:
- Masukkan enam nilai input
- Klik Prediksi
- Voila! Output berupa angka antara 0 dan 1 akan muncul
Jika ≥ 0.5 → diklasifikasikan sebagai Positif (1)
Jika < 0.5 → diklasifikasikan sebagai Negatif (0)
Aplikasi ini juga menyediakan fitur Batch Prediksi jika ingin menguji banyak data sekaligus.
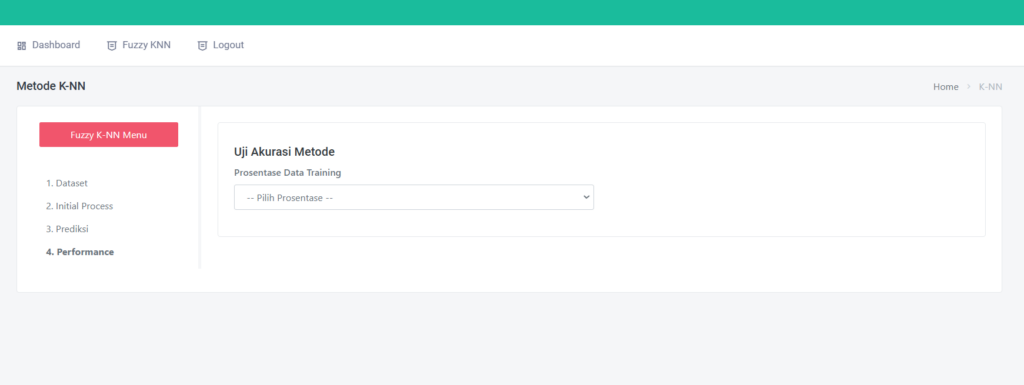
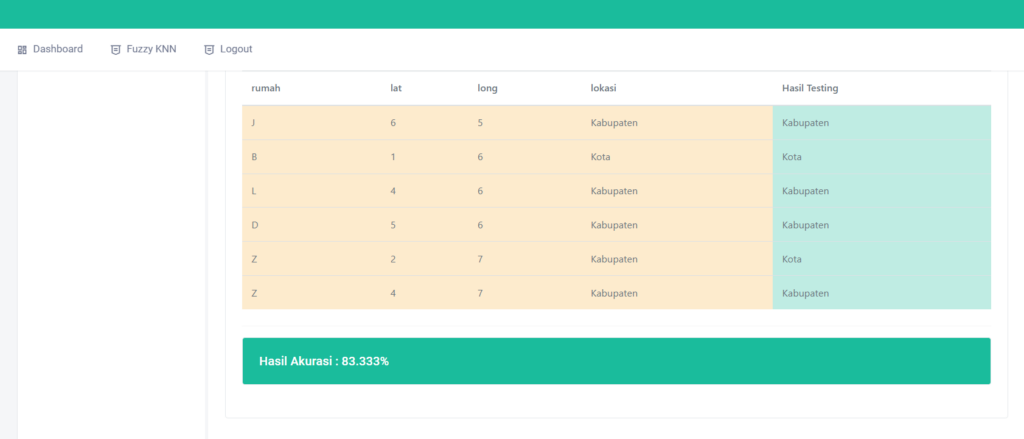
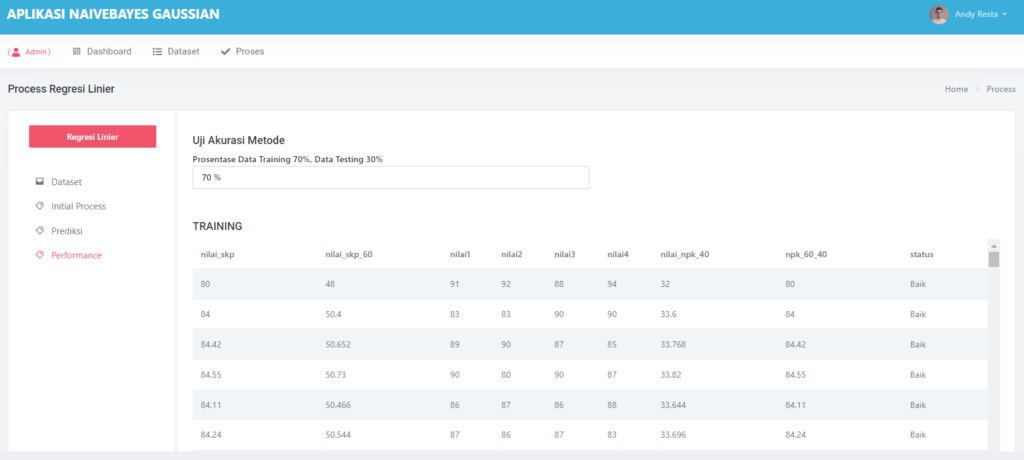
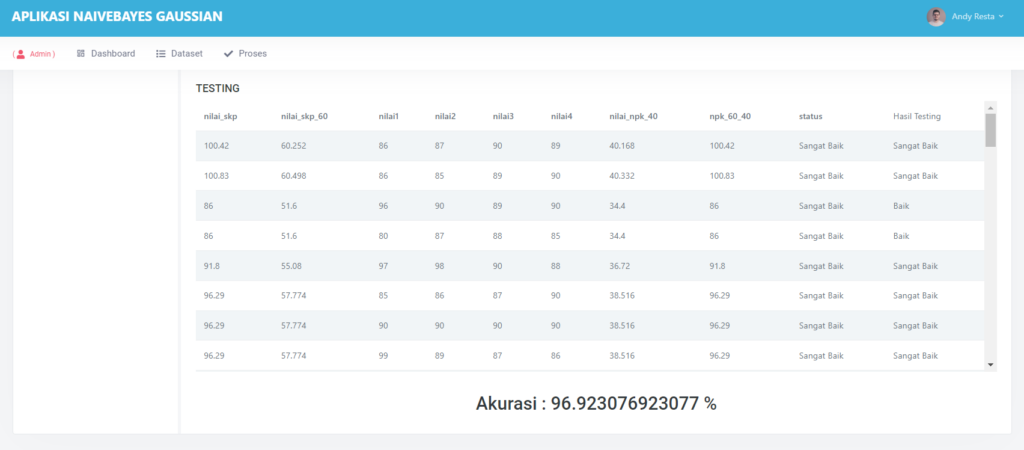
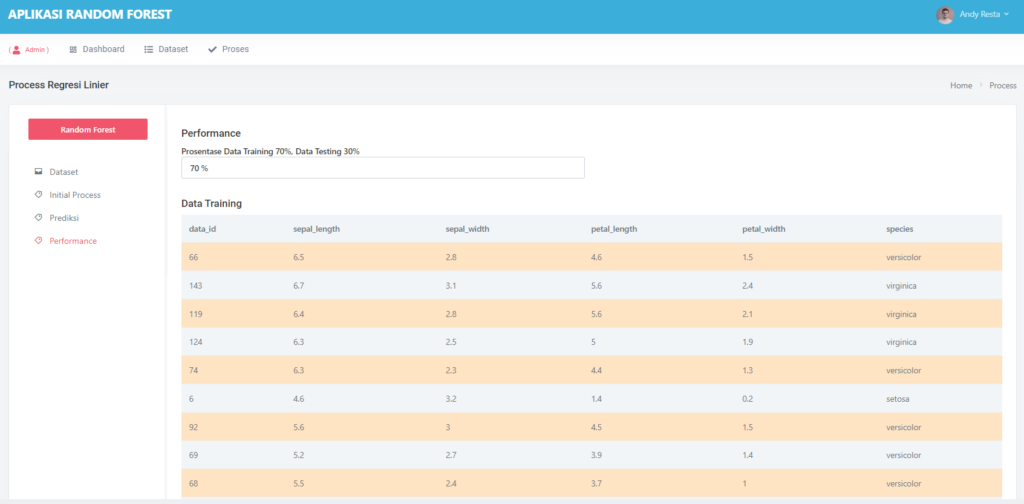
🧪 Evaluasi Model: Seberapa Hebat Model Kita?
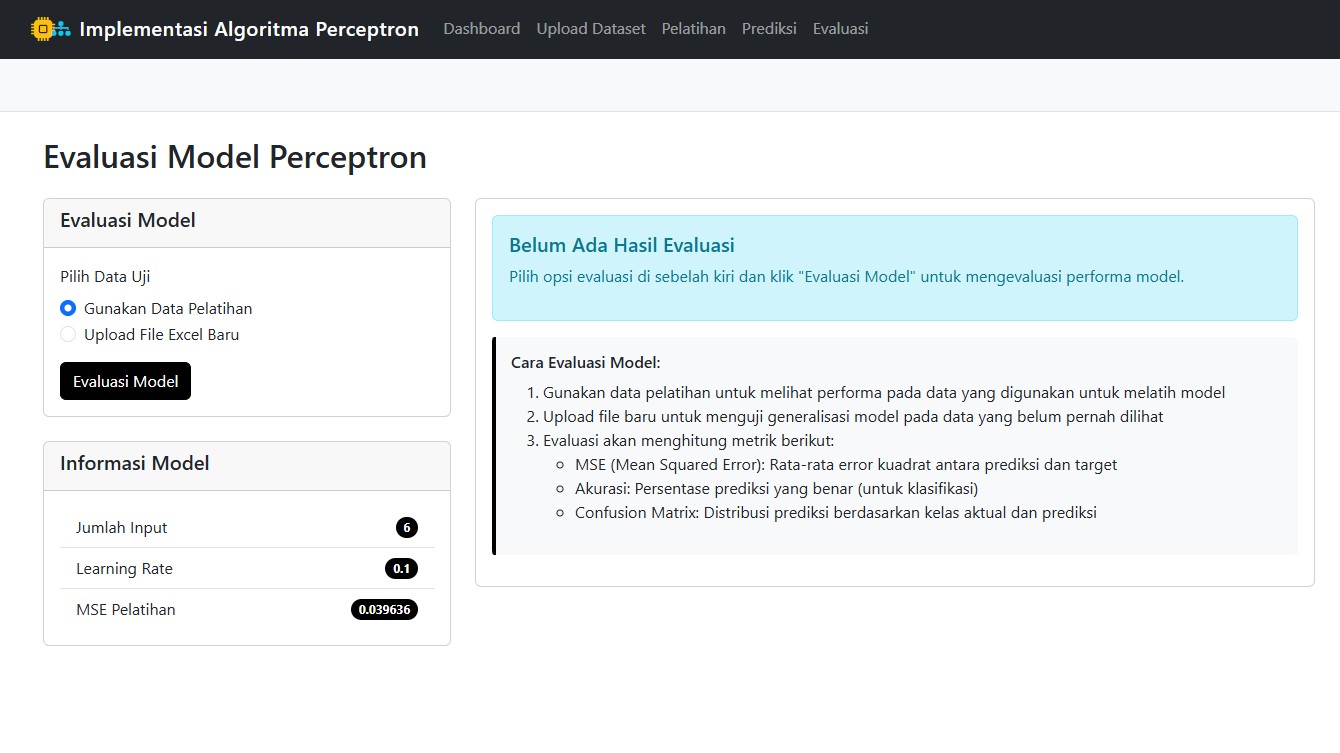
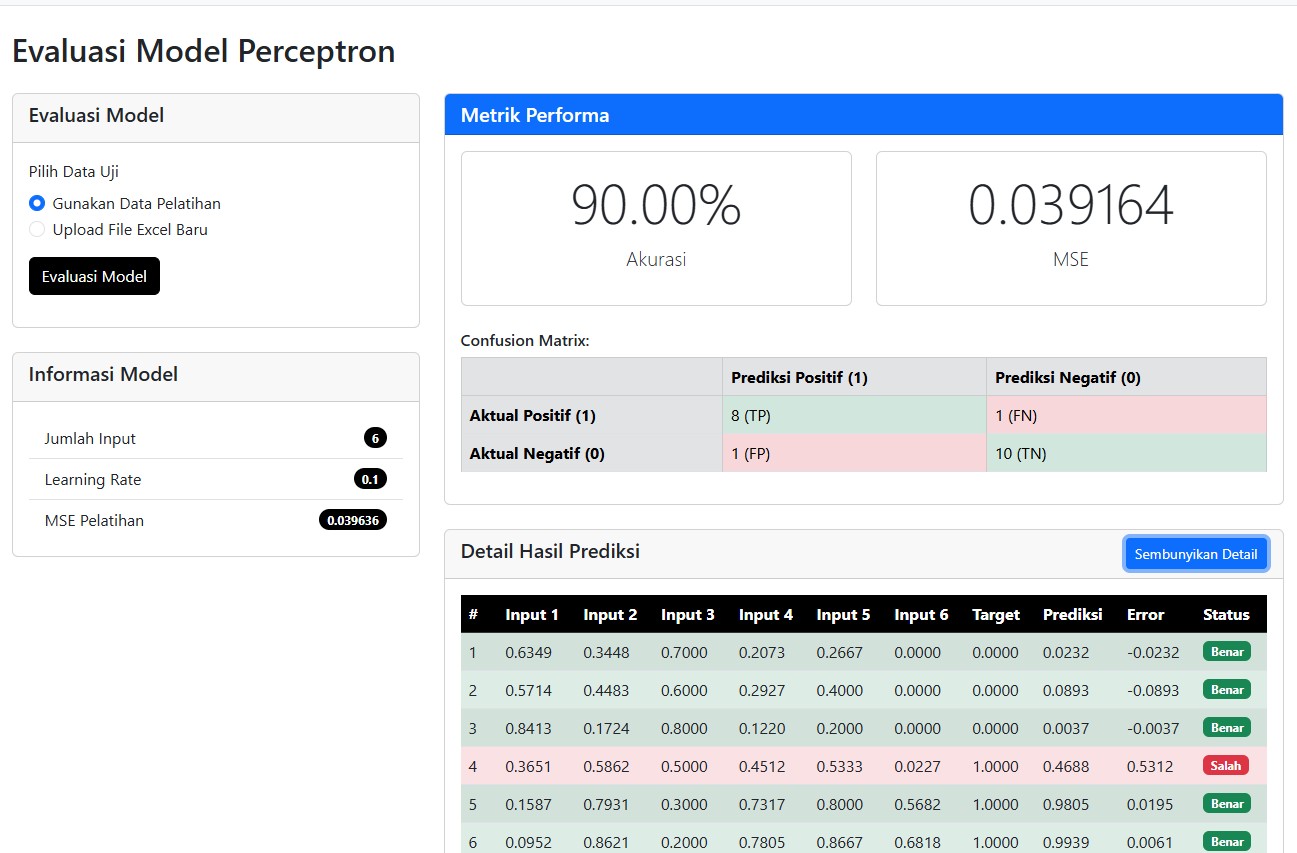
Untuk tahu seberapa baik model bekerja, aplikasi menyediakan fitur evaluasi lengkap:
- MSE (Mean Squared Error)
- Akurasi
- Confusion Matrix
Contohnya, model pada pengujian kami berhasil mencapai akurasi 90% dengan MSE hanya 0.039 — hasil yang sangat baik untuk data sederhana!
🔍 Mengapa Aplikasi Ini Layak Dicoba?
✅ Tidak butuh install Python atau library ML berat
✅ Bisa dijalankan di localhost PHP
✅ Mudah digunakan untuk pembelajaran dan eksperimen
✅ Cocok untuk tugas akhir, skripsi, atau praktikum kuliah
✅ Memvisualisasikan proses machine learning secara lengkap
🎁 Ingin mencoba aplikasinya sendiri?
Klik tautan di bawah ini untuk mendapatkan aplikasinya: